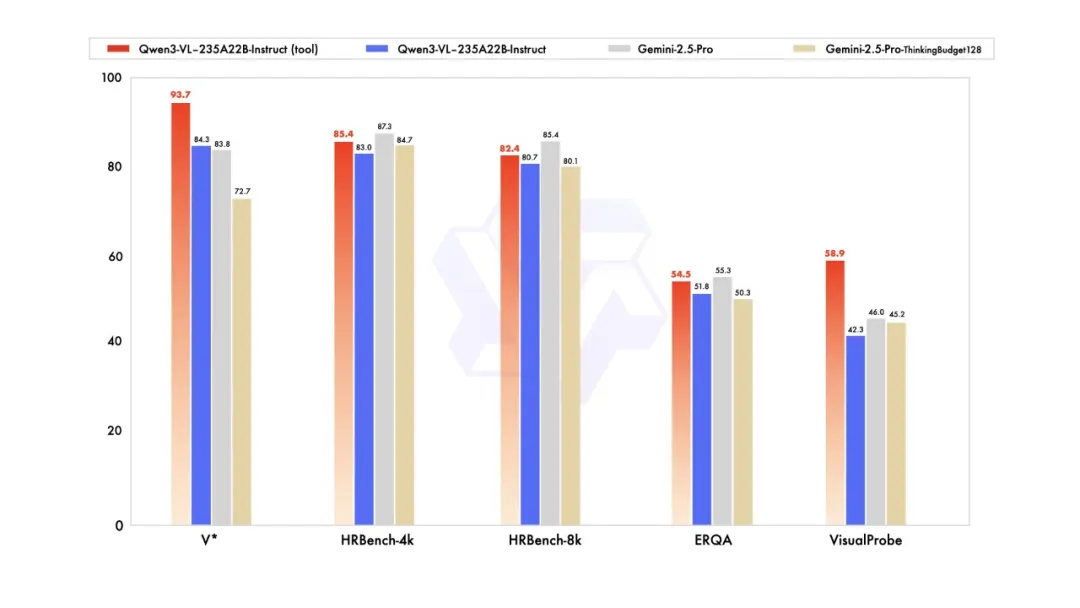
アリババのTongyi Labは、視覚言語モデルの新世代「Qwen3-VL」を公開した。旗艦のQwen3-VL-235B-A22BはMixture-of-Experts構成で、InstructとThinkingの2系統を同時にオープンソース提供。GUI要素理解とツール呼び出しを組み合わせた視覚エージェント能力、相対座標化した2Dグラウンディングと3D境界ボックス推定による空間推論、長いコンテキスト対応(標準256K/最大100万トークン拡張)を中核に据える。
モデルは長尺動画の時系列理解を強化し、秒単位でのイベント定位を可能にする。Thinking系はSTEM・数理推論に重点を置き、Instruct系は汎用視覚タスクで高水準の成績を示す。多言語OCRの対応範囲を拡大し、難条件の実写でも安定性を高めたほか、HTML/CSS/JSや図表コード生成などの視覚コーディングも実演例で示した。
アーキテクチャ面では、時間・高さ・幅の位置符号化を交互配置するMRoPE-Interleave、ViT多層特徴をLLM複数層へ注入するDeepStack的設計、テキスト時間スタンプと映像フレームの細粒度整合による時間理解の強化を実装。長動画理解や細粒度認識、文書解析の効率と精度を底上げした。APIはAlibaba CloudのModel Studio経由で提供され、オープンソース配布により研究・実装双方での適用拡大が見込まれる。