シャオミ(Xiaomi)は音声分野における画期的成果として、ネイティブなエンドツーエンド音声大モデル「MiMo-Audio」をオープンソースで公開した。従来の音声AIは大規模なラベル付きデータに依存し、汎用化能力に課題を抱えてきたが、MiMo-Audioは1億時間規模の無損失圧縮音声データを用いた革新的な事前学習により、初めて少数サンプルでのタスク適応を実現した。研究チームはこれを「音声分野のGPT-3に相当する転換点」と位置付けている。
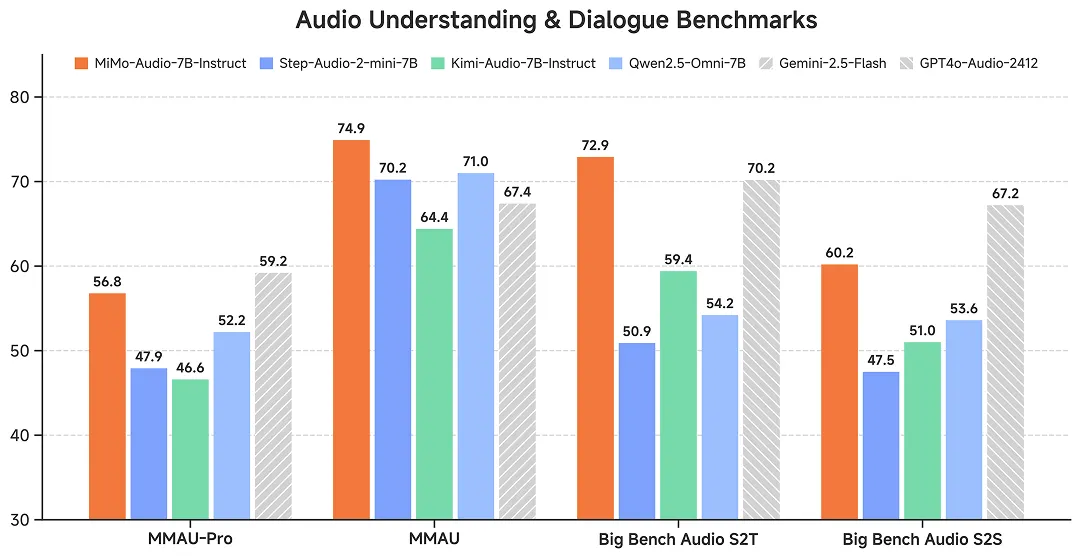
評価においても成果は顕著で、音声理解ベンチマークMMAUでGoogleのクローズドソースモデルGemini-2.5-Flashを超え、さらに複雑な推論を要するBig Bench Audio S2TではOpenAIのGPT-4o-Audio-Previewを上回った。また、音声理解と生成の双方に「思考」機構を導入した初のオープンソースモデルであり、人間に近い自然な会話、感情表現、対話適応を可能にしている。
公開範囲は広く、MiMo-Audio-7B-BaseおよびInstructモデル、1.2BパラメータのTokenizer、技術レポート、評価フレームワークを含み、Hugging FaceやGitHubを通じて利用可能となっている。これにより研究者や開発者は、音声AIにおける少数サンプル学習や音声エージェント訓練、音声AGIの基盤技術に直接アクセスできる環境を得た。シャオミは今後もオープンソースを継続し、音声AI分野における協調と革新を推進するとしている。