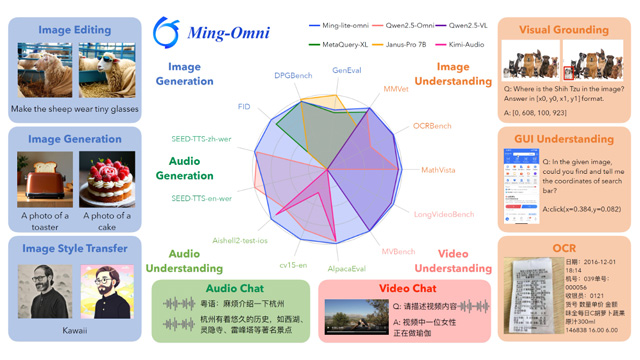
アントグループが公開した「Ming-Omni」は、画像・音声・テキスト・動画という複数のモダリティを統合処理できるマルチモーダルAIモデルだ。各モダリティに専用エンコーダーを設けてトークンを抽出し、MoE(Mixture-of-Experts)構造を持つ大規模言語モデル「Ling」によって処理される。
Lingは各モダリティ専用のルーターを備え、情報の衝突を回避しながら一体的な融合を可能にしている。これにより、従来必要とされた個別モデルの切り替えや微調整を不要にし、統一フレームワークでの柔軟なタスク実行を実現した。
軽量版「Ming-lite-omni」は、アクティブパラメータ数28億でありながら、画像理解ではQwen2.5-VL-7Bと同等の性能を示し、音声理解ではQwen2.5-OmniやKimi-Audioを上回る結果を記録。さらに、画像の生成やスタイル変換、自然音声生成など多様なタスクにも対応可能だ。
このようにMing-Omniは、GPT-4oと並ぶモダリティ対応範囲を備えた初のオープンソースモデルとして、研究・産業応用の両面で今後の展開が期待されている。