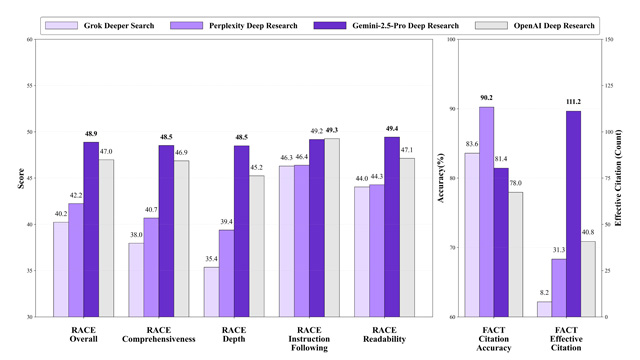
問小白開発チームと中国科学技術大学は、調査系AIエージェントを比較評価する新ベンチマーク「DeepResearch Bench」を発表した。本ベンチマークは100の専門調査タスクを用い、RACE(文章品質)とFACT(引用の網羅性と正確性)の2軸で評価する。
Gemini-2.5-ProはRACE評価で48.88点を獲得し総合首位に立ち、Perplexityは引用精度で優れた結果を示した。またClaude 3.7 Sonnetは、検索機能を持つLLMの中で最もバランスの良いパフォーマンスを記録した。
評価手法の信頼性を確認するため、大学院生による人間評価との一致検証も実施。RACEのスコアは99.54%のPearson一致率を示し、従来のLLM-as-a-Judge方式を大幅に上回った。
本ベンチマークは論文・評価コード・タスクデータを含めて全てオープンソース化されており、今後もタスクの拡充や評価手法の強化を通じて、AIエージェントの性能可視化に貢献していくとされる。