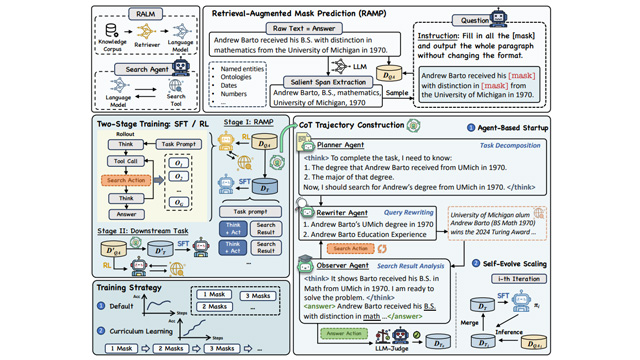
アリババ傘下のTongyi Lab(通義実験室)は、検索と推論の統合能力を強化する新たな事前学習フレームワーク「MaskSearch」を発表し、オープンソースとして公開した。このフレームワークは「RAMP(Retrieval-Augmented Masked Prediction)」という検索強化型マスク予測タスクを中心に据え、検索を活用して文中の欠損情報を補完する訓練を通じて、タスク分解や推論スキルを育成する。
MaskSearchは教師あり微調整(SFT)と強化学習(RL)の両手法に対応。SFTでは複数エージェントによる思考チェーン合成と蒸留を併用し、RLではQwen2.5-72B-Instructモデルによる報酬設計を導入。検索・推論性能を安定的に高めた。
実験結果では、HotpotQAやBamboogleなどのデータセットで、小規模なQwen-1Bモデルが大規模モデルQwen-7Bに迫る精度を発揮。さらに、掩码の数に応じたカリキュラム学習が推論能力の向上に寄与した。
報酬設計では、token単位の召喚率に基づく手法は回答の冗長化を招いた一方、モデル評価型報酬は出力の質と安定性の両立に成功した。コードと技術論文はそれぞれGitHubおよびarXivにて公開中で、Qwenベースで再現可能なトレーニングパイプラインも整備されている。