中国のAI企業DeepSeekは、同社の大規模言語モデル「DeepSeek-R1」のアップグレード版である「DeepSeek-R1-0528」を正式に公開した。今回の更新では、2024年12月リリースのV3 Baseモデルを基盤に、後訓練でより多くの計算資源を投入。これにより、推論能力、数学・プログラミング・一般的な論理タスクへの適応力が大きく向上した。
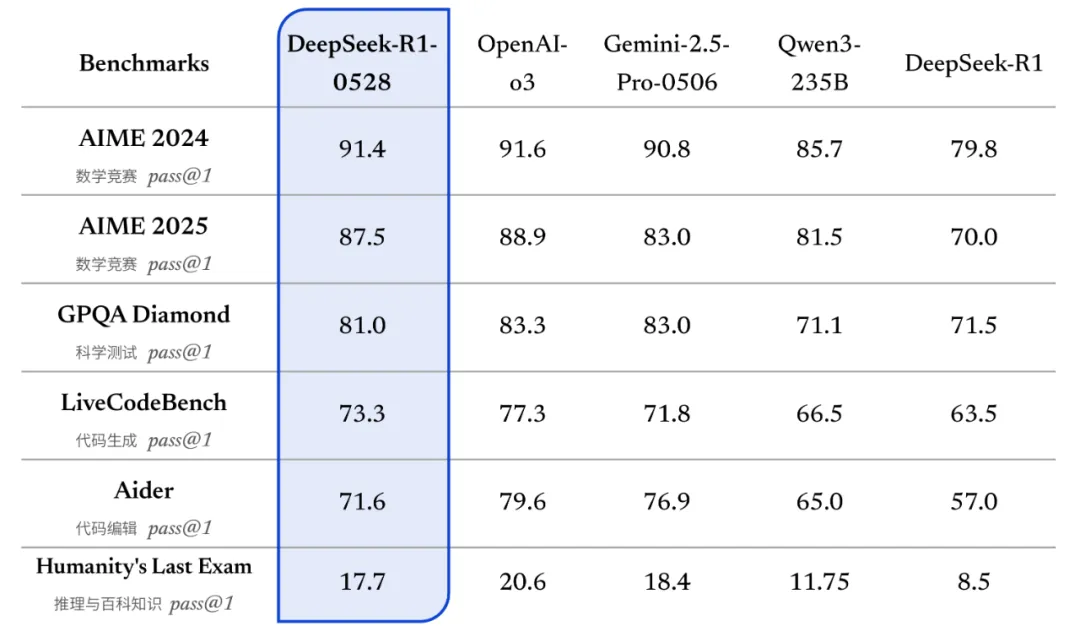
特に注目すべきは、複雑な推論力の向上だ。AIME 2025試験では、旧版の正答率70%に対し、新版では87.5%を記録。1問あたりの平均トークン使用量も12Kから23Kへと増加し、より深い思考過程を経ていることを示している。さらに、この思考過程を蒸留して作られた8Bサイズの「DeepSeek-R1-0528-Qwen3-8B」も好成績を残し、Qwen3-235Bと同等レベルの精度を発揮した。
今回のアップグレードでは、生成結果に含まれる事実誤り(幻覚)の発生率も大幅に低下。従来比で最大50%改善され、要約や読解などでもより信頼性の高い出力が得られる。また、小説やエッセイなどの創作文体にも最適化され、構成や文体において人間らしさが際立つ。
実装面では、ツール使用やコード生成などの機能も改良。APIではFunction CallingとJSON出力をサポートし、出力長の最大値が64Kに拡張された。APIユーザーにはmax_tokensの再設定が推奨されている。
DeepSeek-R1-0528はMITライセンスの下でオープンソース化されており、ModelScopeおよびHuggingFaceでダウンロード可能。従来と同じく、モデル出力や蒸留を活用した再学習も許可されている。公式プラットフォームでは64Kの文脈長が提供されているが、サードパーティを通じて128Kの長文処理にも対応できる。