アリババ傘下のTongyi Labが開発した空間音声生成AI「OmniAudio」は、360度映像からFirst-order Ambisonics(FOA)形式の空間音声を直接生成できる。従来の音声生成が立体音声止まりだったのに対し、本モデルは映像内の空間情報を解析し、臨場感ある3D音響体験を提供する。
この技術の中核には、103,000本以上の360度映像と288時間に及ぶFOA音声からなるデータセット「Sphere360」がある。静止動画や音声ノイズを自動検出・排除する高精度なアルゴリズムも導入されており、視聴覚の一致精度を高めている。
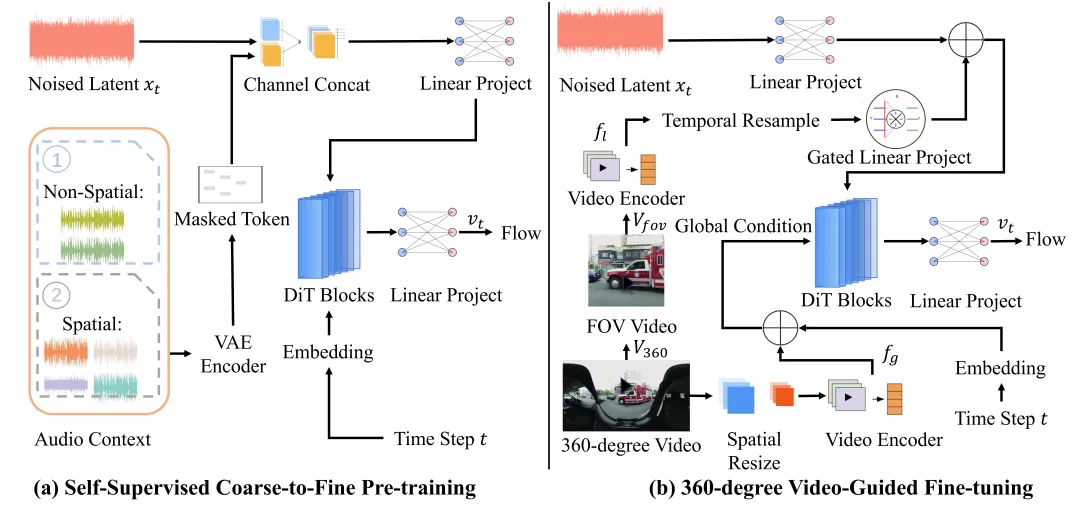
OmniAudioは、自律学習による粗学習と、双分岐構造を用いた教師あり微調整という2段階の訓練戦略を採用。グローバルな視野とFOV(Field of View)から得られるローカルな情報を同時に取り込むことで、音源方向の精度と音質を大幅に向上させた。
評価実験では、FDやKL、方向誤差など複数の客観指標で従来手法を大きく凌駕。主観評価でもMOSスコアで最高値を記録し、画面との音の同期性や明瞭度で圧倒的な性能を示した。さらに、コードとデータはGitHubでオープンソースとして公開されており、研究と実装の両面で再現性が高い。
OmniAudioは、今後のVR・AR体験における音響表現を一変させる可能性を秘めており、空間音声の新たなスタンダードとなることが期待される。