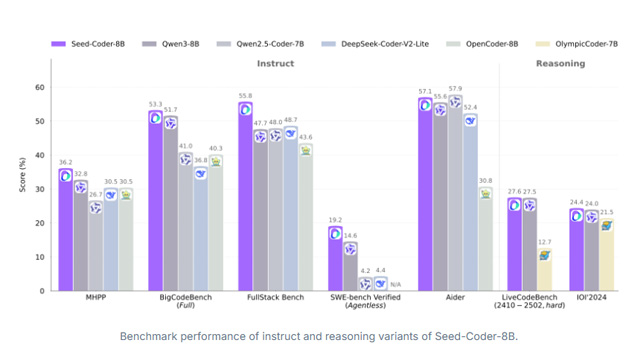
バイトダンスのAI研究部門「Seed」チームは、コード生成に特化した大規模言語モデル「Seed-Coder」を初めてオープンソースとして公開した。モデルはLLaMA 3ベースで、約8.2Bのパラメータを持ち、コード生成分野においてQwen3を上回る性能を発揮。Base、Instruct、Reasoningの3種のモデルバリエーションが提供されており、すべてMITライセンスのもとGitHubおよびHugging Face上にて公開されている。
Seed-Coder最大の特徴は、コードデータの収集からフィルタリング、学習までをモデル自身が主導する「モデル中心のデータ管理」パラダイムにある。GitHubやインターネット上のコード関連文書から収集した生データは、ファイルレベル、リポジトリレベル、コミットデータ、Web文書の4種に分類され、それぞれに対して構文エラーの除去、重複排除、品質スコアリングといった高度な前処理が実施される。コードの品質評価には、DeepSeek-V2-Chatをベースにしたスコアリングモデルを採用し、可読性やモジュール性、再利用性などを指標に低品質コードを除外。結果として、約1兆tokenに及ぶ高品質コードコーパスの構築に成功している。
訓練工程は2段階に分かれ、第一段階ではファイル単位およびWebコード文書を用いた基礎訓練を行い、第二段階ではコミット履歴や長文文脈を含む高難度データによってモデルを精緻化する。FIM(Fill-in-the-Middle)やSPM(Suffix-Prefix-Middle)といった補完型タスクも導入され、長文文脈理解能力の強化が図られている。また、用途別に特化した派生モデルも用意されており、「Seed-Coder-Instruct」はSFT(教師あり微調整)とDPO(直接好み最適化)によって指示追従性能を強化、「Seed-Coder-Reasoning」はLongCoT(長鎖思考)と強化学習により多段階のコード推論能力を向上させている。
技術仕様としては、最大32Kの文脈長、6兆トークンでの事前学習、GQA(Grouped Query Attention)を導入した構造で、効率と性能のバランスが取られている。GitHub上の公式リポジトリでは、モデルコードやデータ前処理スクリプト、技術論文(PDF)が公開されており、Hugging Faceの専用ページからは、各モデルの推論APIや事前学習済みの重みファイルが誰でも利用可能となっている。
バイトダンスはこのSeed-Coderに加え、動画生成モデル「Seaweed」や推論強化モデル「Seed-Thinking-v1.5」、清華大学と共同開発したマルチタスク対応エージェント「UI-TARS」なども続々と公開。さらに、2024年にはAGI志向の長期研究プロジェクト「Seed Edge」を立ち上げ、計算資源と独立性を備えた研究環境を提供するなど、オープン化と次世代AI研究へのコミットを強めている。これら一連の取り組みは、AIのオープン性、普遍性、原始的創造性を重視する新たな潮流の一端を示すものであり、中国発の大規模コード生成モデルとして国際的な注目を集めている。