上海AI LabとSenseTime(商湯科技)は、マルチモーダル大言語モデル「InternVL3」を正式に発表した。InternVL3は、従来のLLMベースのマルチモーダルモデルと異なり、言語とマルチモーダル能力を統合的に学習する「原生マルチモーダル事前学習」方式を採用している。これにより、事後的な視覚モジュールとの調整や補完が不要となり、効率的かつ整合性の高い学習を実現した。
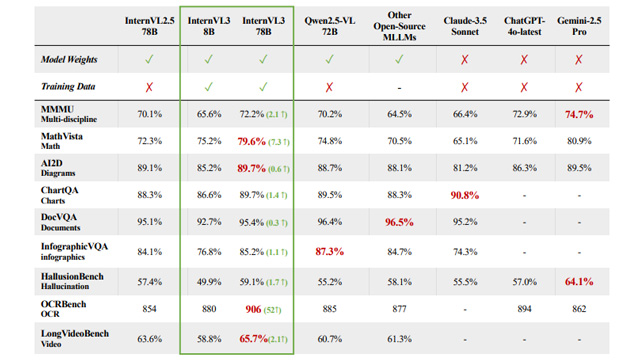
モデル構成は、ViT(Vision Transformer)、MLP(多層パーセプトロン)、LLMから構成され、視覚情報には「可変ビジュアル位置エンコーディング(V2PE)」を採用。これにより、マルチモーダル文脈の拡張性が向上し、視覚情報の効率的な位置管理が可能になった。大規模モデル「InternVL3-78B」は、ベンチマークMMMUにおいて72.2点を記録し、既存の開源MLLMを上回る成果を示した。
訓練にはQwen2.5およびInternLM3を基にしたLLMを使用し、視覚エンコーダはInternViT系列を採用。さらにSFT(有監督微調整)とMPO(混合選好最適化)により、推論や対話能力も強化されている。評価においては、OCR、数学、図表理解、動画処理、空間推論、GUI理解など幅広いタスクで高いスコアを記録し、特にMMMUやOCRBenchではトップレベルの性能を発揮。
また、InternVL3はQwen2.5-VLやChatGPT-4oなどの商用モデルとも比較可能な競争力を持ち、GPT-4oを上回るケースも見られた。言語能力においても、従来のQwen2.5系列を上回る結果が報告されており、マルチモーダルとテキストの同時訓練が効果的であることが示された。
今後は、InternVL3の学習済みデータとモデル重みをコミュニティに向けて公開する予定であり、マルチモーダル大言語モデル分野のオープンイノベーション促進が期待されている。