Kunlun Tech(昆侖万維)のSkyworkチームは、推論能力に特化した大規模言語モデル「Skywork-OR1」シリーズを完全オープンソースで公開した。本シリーズには、数学推論に特化したSkywork-OR1-Math-7B、汎用型のSkywork-OR1-7B-Preview、高度な複雑タスクに対応するSkywork-OR1-32B-Previewが含まれる。いずれもGitHubとHugging Faceにて、モデル本体だけでなく訓練データとコードを含む完全オープンソースで提供されている。
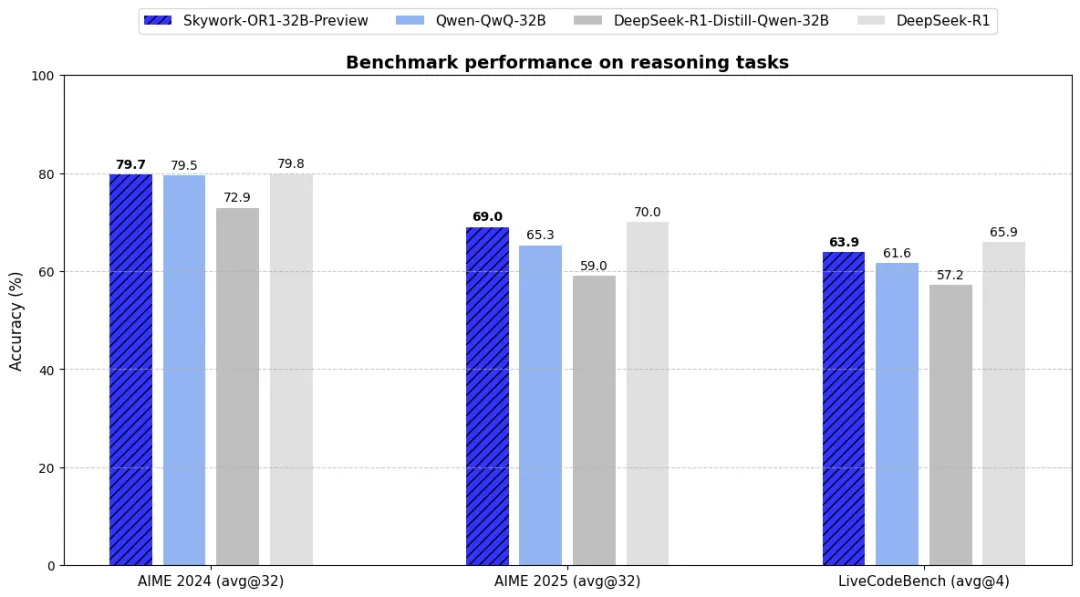
評価指標としては、従来のpass@kよりも安定性や実用性を詳細に測るavg@kを導入。数学ベンチマークのAIME24/25や、コード生成タスクのLiveCodeBenchで高いスコアを記録し、特にSkywork-OR1-32Bは、QwQ-32Bを上回りながら、パラメータ数671BのDeepSeek-R1に匹敵する性能を示した。
Skywork-OR1の開発には、Skyworkチームが長年蓄積した訓練技術が活かされている。技術ブログによれば、モデル訓練にはGroup Relative Policy Optimization(GRPO)を採用し、多段階訓練や探索性強化、KL損失の排除など、多くの独自技術が投入された。特に、高品質データセットの構築においては、数十万題規模の数学・コード問題を収集・精選。問題の正確性・検証可能性・挑戦性を基準にフィルタリングを行い、さらに人手とLLMによるハイブリッド評価によって品質を保証している。
訓練プロセスでは、トークン長を段階的に拡張するmulti-stage訓練戦略、低品質データ除去による学習効率向上、高温度サンプリングによる多様性保持、自適応的entropy制御といった技術が導入されており、トレーニングの安定性と性能の最大化が図られている。加えて、Token-level policy lossへの最適化によって、生成長への偏りを排除し、一貫性ある最適化が実現されている点も技術的な特徴として強調されている。
Kunlun Tech(昆侖万維)は2023年より「All in AGI・AIGC」戦略のもと、Skyworkシリーズを中心としたオープンソース展開を加速させており、Hugging Face上には既に22モデルと6データセットを公開している。今後も、通用人工知能の構築と技術的自立を目指して、推論能力のさらなる向上とコミュニティとの連携を進めていくとみられる。