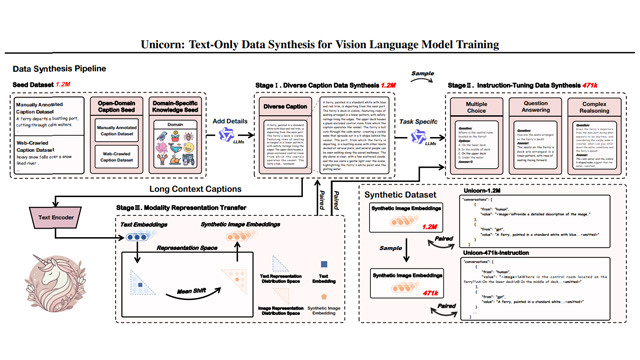
ARグラス開発企業のXrealが、西湖大学の研究チームと共同で、視覚言語モデル(VLM)訓練のための新たなアプローチ「Unicorn」を発表した。Unicornは、実画像に依存せず、純粋なテキストから多モーダル訓練データを合成するフレームワークであり、マルチモーダルAIの学習コストとデータ構築の負担を劇的に軽減する。
Unicornは「多様化テキスト生成」「指令データ構築」「画像表現の合成」という三段階の統合プロセスを通じて、計167万件の合成データを生成。具体的には、オープン分野および専門領域の記述文を大規模言語モデル(Qwen2.5 72B)で拡張し、多様な説明文を生成。その後、選択肢問題・QA・推論形式の指令形式に変換したうえで、CLIP表現空間でテキストから画像の意味表現を再構成した。
こうして構築された120万件の「Unicorn-1.2M」と、47.1万件の「Unicorn-471K-Instruction」は、どちらも一切の実画像を使わずに合成された純粋なテキスト起点の多モーダルデータとなる。これらを用いて訓練された「Unicorn-8B」は、ScienceQAやPOPEなど複数のベンチマークで他のSOTAモデルと同等、あるいはそれ以上の性能を示した。
特筆すべきは、Unicornが実現したコスト効率と拡張性の高さだ。従来の画像+テキスト対による訓練に比べ、APIコストを10分の1以下に抑え、データ生成時間も数分の1、ストレージ使用量は96%削減された。また、文長の分布や多様性、専門知識のカバレッジでも高水準を維持し、合成データの質が検証された。
さらに、「モーダルギャップ理論」に基づく表現変換により、テキストベースで生成された画像表現と実画像表現との乖離を補正。iNaturalist-VQAなどの分野特化ベンチマークでも性能向上が確認され、分野知識の精密な注入能力も評価された。
現在、Unicornの実装コードはGitHub上で近日中に公開予定とされており、XrealのAR技術とAI研究の融合が今後のマルチモーダルAI開発に与える影響が注目される。