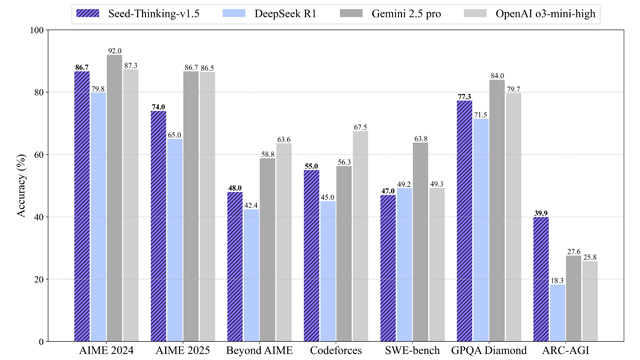
バイトダンスは2025年4月、論理推論に特化した新しい大規模AIモデル「Seed-Thinking-v1.5」を発表した。同モデルは、数学、プログラミング、科学常識といった論理的分野において、DeepSeek R1やGPT-4 o3などの強力な既存モデルを上回る性能を示している。GitHub上では、同モデルの評価データセットと詳細なベンチマーク結果も併せて公開された。
Seed-Thinking-v1.5の構造は、タスクに応じて各専門モジュールを動的に呼び出すMoE(混合エキスパート)方式を採用し、全体の計算負荷を抑えながらも領域ごとの専門性を高めている。モデルは2000億パラメータを持ちつつ、実際の推論では20億パラメータのみを活性化する設計で、効率と性能のバランスを実現している。
訓練データは高難易度の数学・STEM問題10万問や、Codeforcesのコンテスト問題などから選別され、曖昧な問題の除去や設問形式の変換(選択式から記述式)によって、より思考力を試す構成となっている。
また、強化学習にはVAPOとDAPOという二つの学習フレームワークを導入し、論理的正解のある問題と、創作などの主観的なタスクの両方に対応。訓練中の性能ブレを±10%から±1%まで安定させ、信頼性を大きく向上させた。
Seed-VerifierとSeed-Thinking-Verifierという二重検証機構により、単に“正解らしい”答えではなく、推論過程そのものの妥当性を検証できるように設計されている。創作分野では人間の好みに基づく比較法での評価が採用され、ユーザー満足度も8%向上したという。
さらに、流式処理システムや並列処理によって、複雑な問題チェーンや超長文入力にも対応可能となっており、実務における利用範囲も広がっている。
GitHubでは、100問からなる超高難易度の数学ベンチマーク「BeyondAIME」や、Codeforcesの12回分の評価データセットが公開されており、推論系モデルの標準化・公正評価の促進を目指している。これにより、今後の推論AIモデル開発における共通の評価基盤となる可能性がある。
Seed-Thinking-v1.5は、単なる性能の向上だけでなく、「思考の妥当性」と「応用の柔軟性」を重視した技術設計が特徴的であり、今後の推論型AIの技術潮流に大きな影響を与えると見られている。