バイトダンスのDoubao(豆包)チームは、コード修復分野における初の多言語対応ベンチマーク「Multi-SWE-bench」をオープンソースとして公開した。従来のSWE-benchがPython言語に限定されていたのに対し、Multi-SWE-benchはJava、C、C++、Go、Rust、TypeScript、JavaScriptの7言語を対象に、1,632件の実例を収録。各修復タスクには難易度(Easy/Medium/Hard)が設定され、実行環境もDockerで完全再現可能な構成とした。
このデータセットは、GitHub上の実際のissueとPull Requestをもとに約1年かけて構築され、68名の専門開発者による二重検証を経て信頼性を担保。現実のソフトウェア開発に即した多言語環境下での評価を可能にすることで、大規模言語モデル(LLM)の汎用性や応用力の限界を測る指標となる。
加えて、Doubao LLM(豆包大模型)チームは、強化学習(RL)による訓練環境として「Multi-SWE-RL」も同時公開。4,723件のRL対応タスクを収録し、ワンクリックで再現可能なDocker環境や、自動評価ツール、RLフレームワークとの接続機能を備える。これにより、単なるデータ提供にとどまらず、学習環境と運用基盤を統合した総合的なプラットフォームを構築している。
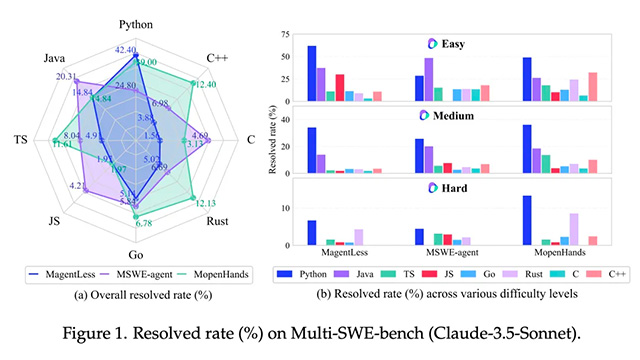
arXivに公開された論文では、Multi-SWE-benchの構成方針とその設計思想を詳述しており、GitHubではデータ構築ツールや構成コードをすべて確認可能。さらに、スコア一覧ページでは、LLM各種モデルの言語別性能を比較でき、Python以外の言語で著しくスコアが低下する現状が示されている。これにより、今後の自動コード生成AIが直面する技術的課題が浮き彫りとなった。
今後Doubao(豆包)チームは、対象言語や修復タスクの拡張、RL訓練の継続強化を進めるとともに、オープンコミュニティと連携した共同研究を促進していく方針を示している。自動ソフトウェアエージェントの実用化に向けた基盤技術として、多言語対応かつ再現可能な本ベンチマークは、今後の標準となる可能性が高い。