中国のAI企業・StepFunは、マルチモーダル推論モデル「Step-R1-V-Mini」を正式発表した。このモデルは、画像と言語を組み合わせた高度な推論能力を持ちながら、軽量設計により実用性を確保している。画像と言語の両方を入力として受け取り、自然言語で出力を生成する形式で、複雑な因果関係や構造的推論にも対応する。
性能強化のため、Step-R1-V-Miniには2つの重要な訓練手法が導入されている。まず、「マルチモーダル強化学習」では、PPO(Proximal Policy Optimization)アルゴリズムをベースに、画像空間内での推論に対し「検証可能な報酬(verifiable reward)」を導入。これにより、視覚的な因果関係や誤認の問題に強くなった。次に、環境フィードバックを活用した大規模なマルチモーダル合成データを作成し、視覚とテキスト推論の両面を並行して鍛えることで、いわゆる「性能のシーソー問題(片方が上がると片方が下がる)」を回避した。
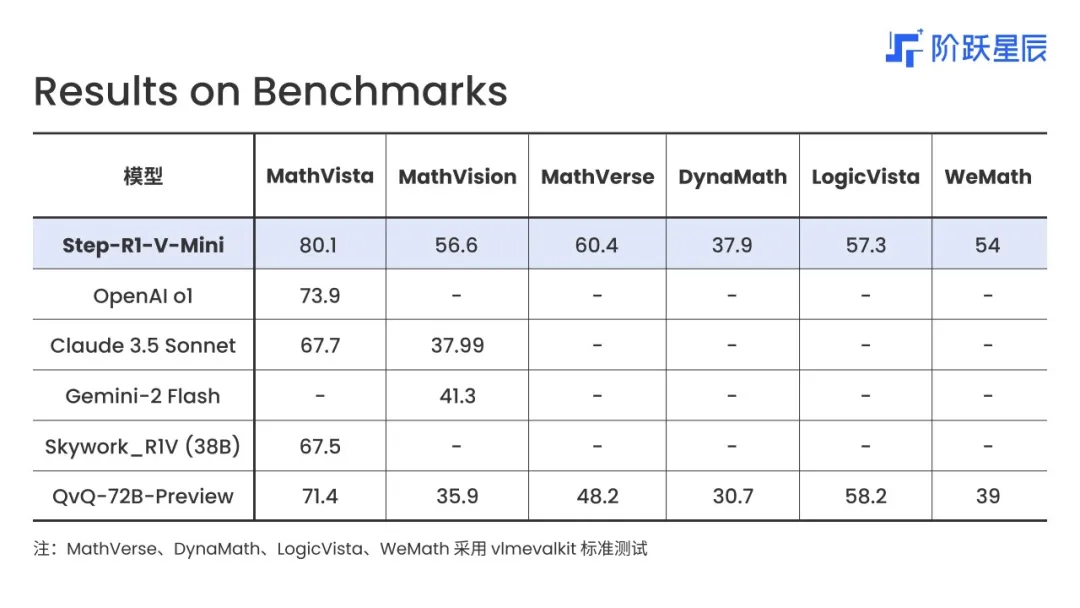
ベンチマーク結果からも、同モデルの優位性が確認できる。添付画像によると、Step-R1-V-Miniは視覚推論系ベンチマーク「MathVista」「MathVision」「MathVerse」「DynaMath」「LogicVista」「WeMath」のすべてにおいて高スコアを記録しており、特にMathVisionでは56.6ポイントで中国国内トップに立った。MathVistaでは80.1、LogicVistaでは57.3、WeMathでは54と、いずれも他の先進モデルを上回る結果となっている。
さらに公開された事例では、スタジアム写真から「ウェンブリー・スタジアム」と試合情報を推論するほか、料理画像から具体的な材料と分量を特定、図形の配置から正確に物体数を数えるなど、多様な推論能力を実証している。
現在、Step-R1-V-MiniはStepFun AIのWebインターフェース上で利用可能であり、開発者向けにAPIも提供されている。今後もStepFunは推論モデルの改良を継続し、マルチモーダルAIの実用化をさらに推進していくと見られる。