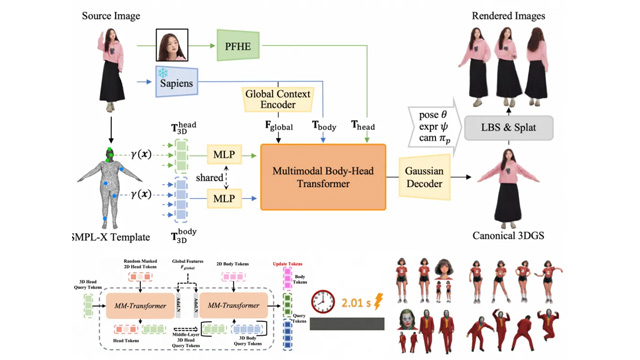
アリババの研究機関「Tongyi Lab」は、1枚の静止画像から数秒で高精度な3Dデジタルヒューマンを生成できる2つのAIモデル「LHM(Learnable Human Model)」と「LAM(Learnable Avatar Model)」を公開した。LHMは、人物写真を基に動作可能な3Dガウス人体を出力するモデルで、骨格構造との連動によりリアルなモーション再現が可能。一方、2025年4月に新たに発表されたLAMは、写真1枚から対話可能な3Dアバターを構築できるモデルで、音声・表情連動型のインタラクティブなキャラクター生成を実現する。
LHMでは、単眼画像をVision Transformerで分割・エンコードし、SMPL-Xベースの人体先験モデルを用いてガウス表現の3Dボディを出力する。特徴点には座標偏移や色彩、サイズ、回転ベクトルなどが含まれ、視覚的・動作的に自然なデジタル人間を生成可能。さらに、DINOv2に基づいたHead Tokenization手法で頭部の細部まで再現される。
2D画像と3D情報の融合には、独自の「Body-Head Transformer」構造を採用。SD3の多モーダル学習設計を参考に、Self-Attention機構を通じて、頭部と身体のトークンを統合的に学習する。この構造により、全身の一貫性と自然な動きが担保される。
LHMの応用範囲は広く、スポーツやダンスの動作再現、ゲームキャラクターの生成、バーチャル受付スタッフのような対話インターフェース、さらにはVR空間への展開まで多岐にわたる。一方のLAMは、テキストから音声を合成し、リップシンクや表情制御が可能な3Dチャットアバターを生成。対話型AIのフロントエンドや仮想キャラクターの実装に活用が期待される。
両プロジェクトは完全にオープンソースで、GitHub上でコードとドキュメントが公開されている。ModelScopeでのオンライン体験や、Bilibiliでの導入動画なども用意されており、開発者やコンテンツ制作者がすぐに試せる環境が整っている。