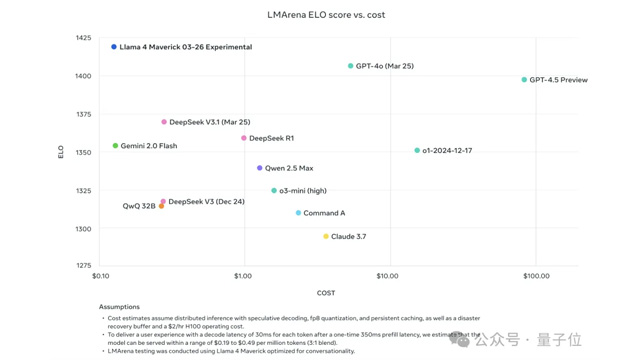
Metaは、MoE(Mixture of Experts)アーキテクチャを初めて採用したLlama 4シリーズを発表し、オープンソースAIモデルの分野でトップの座を奪還した。今回リリースされたのは、中型モデルのLlama 4 Scoutと大型モデルのLlama 4 Maverickの2種類で、いずれも視覚と言語を統合したネイティブな多モーダル対応モデルとなっている。とくにMaverickは、GPT-4oやGemini 2.0 Flashを凌駕し、DeepSeek-V3と同等のコード処理能力をわずか半分のパラメータ数で実現した。単一のH100 GPUで動作可能という点も、導入コストの観点から大きな魅力だ。
Llama 4シリーズは、最大100万トークンの長大なコンテキストウィンドウを持ち、前世代のLlama 3.1(128K)を大きく上回る性能を実現。これにより、多文書要約や大規模コード解析、個人化処理などの応用が期待される。また、12言語への対応や強化学習を活用した後訓練プロセスなど、グローバル展開と実運用を見据えた設計も特徴的だ。
さらに現在訓練中の「Llama 4 Behemoth」は、総パラメータ数2兆というかつてないスケールの超大規模モデルで、ScoutやMaverickの教師モデルにあたる。数学、多言語、視覚処理の各種ベンチマークにおいてGPT-4.5やClaude Sonnet 3.7を超えるスコアを記録しており、完成すれば生成AIの勢力図を一変させる可能性がある。
コスト面でもLlama 4は際立っており、まるで“AI界の拼多多”とも呼ぶべき存在で、DeepSeekを凌駕するほどのコストパフォーマンスを実現している(拼多多=中国の格安ECサイト)。MoEによる効率的な計算資源の活用、FP8精度での高速訓練、軽量な後訓練戦略などにより、性能と価格の両面で他社製品を大きく引き離している。
これにより、Llama 4はオープンソースAIモデルの新たな基準となりつつある。OpenAIやDeepSeekといった他の競合も対応を迫られる中で、Llama 4の登場は今後の大規模AI市場の方向性を大きく左右することになりそうだ。