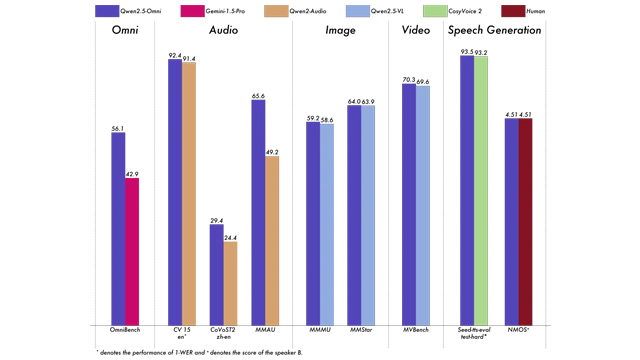
2025年3月、アリババのTongyi Lab(通義実験室)は、同研究チームによる初のエンドツーエンド型・全モーダル対応大規模AIモデル「Qwen2.5-Omni-7B」を正式にオープンソース化した。このモデルはテキスト・画像・音声・動画といった複数のモダリティを同時に処理・理解し、自然言語によるテキストおよび音声をリアルタイムで出力できる。OmniBenchなどの権威あるベンチマークでは、Googleの最新モデルGemini-1.5-Proを上回る性能を示した。
Qwen2.5-Omniは、アリババQwenが開発した「Thinker-Talker」構造を採用している。これは人間の「思考」と「発声」に対応する2つの中枢を持つもので、複雑なマルチモーダル入力をリアルタイムで統合処理する仕組みとなっている。さらに、TMRoPE(Time-aligned Multimodal RoPE)と呼ばれる時間軸に調整された位置エンコーディングを導入することで、音声・動画を含む時間連続的なデータ処理にも最適化されている。
これにより、音声認識・画像理解・動画理解・自然音声生成といった領域で、それぞれの専用モデルを上回る統合的性能を実現。生成音声の評価スコアは4.51と、人間レベルに匹敵する品質を達成した。これらの結果は、Gemini-1.5-ProやClaudeなど他の大手AIモデルと比較しても顕著な差を示している。
Qwen2.5-Omniはモデルサイズがわずか7Bとコンパクトでありながら、数千億パラメータの従来型閉源モデルに匹敵する能力を有している。GitHubではコードやAPI実装例が公開され、ModelScopeでは簡易デモやパラメータ設定の確認が可能。さらにHugging Face上ではモデルの技術仕様・学習条件・性能スコアが詳細に公開されており、グローバルなAI開発者にとって導入障壁が低い。
また、スマートフォンやエッジデバイスにも容易に展開できる設計となっており、教育・医療・製造・サービス分野など、幅広い産業への応用が視野に入る。現在、Qwen2.5-OmniはAlibaba CloudのAPI経由でも使用可能であり、開発者向けにはチャット体験サービス「Qwen Chat」も提供されている。
アリババQwenはこれまでに0.5B〜110B規模の200以上のモデルを開発しており、Qwenシリーズ全体の派生モデル数は世界で10万件を突破。中国国内だけでなく、オープンソースAIコミュニティ全体でも最大規模の貢献を続けている。
Qwen2.5-Omni-7Bの登場は、軽量・高性能・マルチモーダルという次世代AIの方向性を象徴する事例となった。