アリババのTongyi Lab(通義実験室)は、視覚と言語を統合したマルチモーダル大規模言語モデル「Qwen2.5-VL」シリーズにおいて、新たに32Bパラメータ版となる「Qwen2.5-VL-32B-Instruct」を発表し、オープンソースとして公開した。これまでに3B、7B、72Bのバージョンを展開してきた同シリーズにおいて、32Bは性能と運用負荷のバランスを重視したミッドレンジモデルに位置づけられる。ローカル環境でも動作可能な設計で、企業や研究者が独自の環境下で導入・検証しやすいのが特徴だ。
このモデルは、強化学習(Reinforcement Learning)による人間フィードバックを通じて調整された「Instruct」バージョンであり、回答の自然さや文脈理解の正確性が大きく向上している。開発チームによれば、Qwen2.5-VL-32B-Instructは以下の3点において顕著な進化を遂げている。1つ目は、人間の指示により忠実に応答する対話能力。2つ目は、幾何学や数式を含む数学的推論に対する高い解答精度。3つ目は、視覚データ(画像)に対する解析・認識・論理的推定といったマルチモーダル処理の正確さと粒度の細かさである。
実際の応用例として、交通標識の写真をもとに「現在12時、大型トラックでこの道路を走行中。110km先に13時までに到着できるか?」といった現実的かつ推論を要する問いにも対応できる。モデルはまず、画像内の制限速度や時間情報を抽出し、次に距離と平均速度を計算、最後に論理的に結論を導き出すステップを踏む。こうした一連の処理は、従来の画像認識モデルに比べて遥かに文脈依存性と説明性に優れている。
数学分野でも、例えば複雑な立体図形の展開図に関する問題や、数列のパターン認識に基づいた推論問題において、問題構造を分析し、4段階ほどのステップを通じて正解に至る論理的プロセスを実行できる。モデルはただの出力エンジンではなく、思考過程を模倣するようなステップバイステップの推論を行うため、学術的応用や教育分野への展開も期待される。
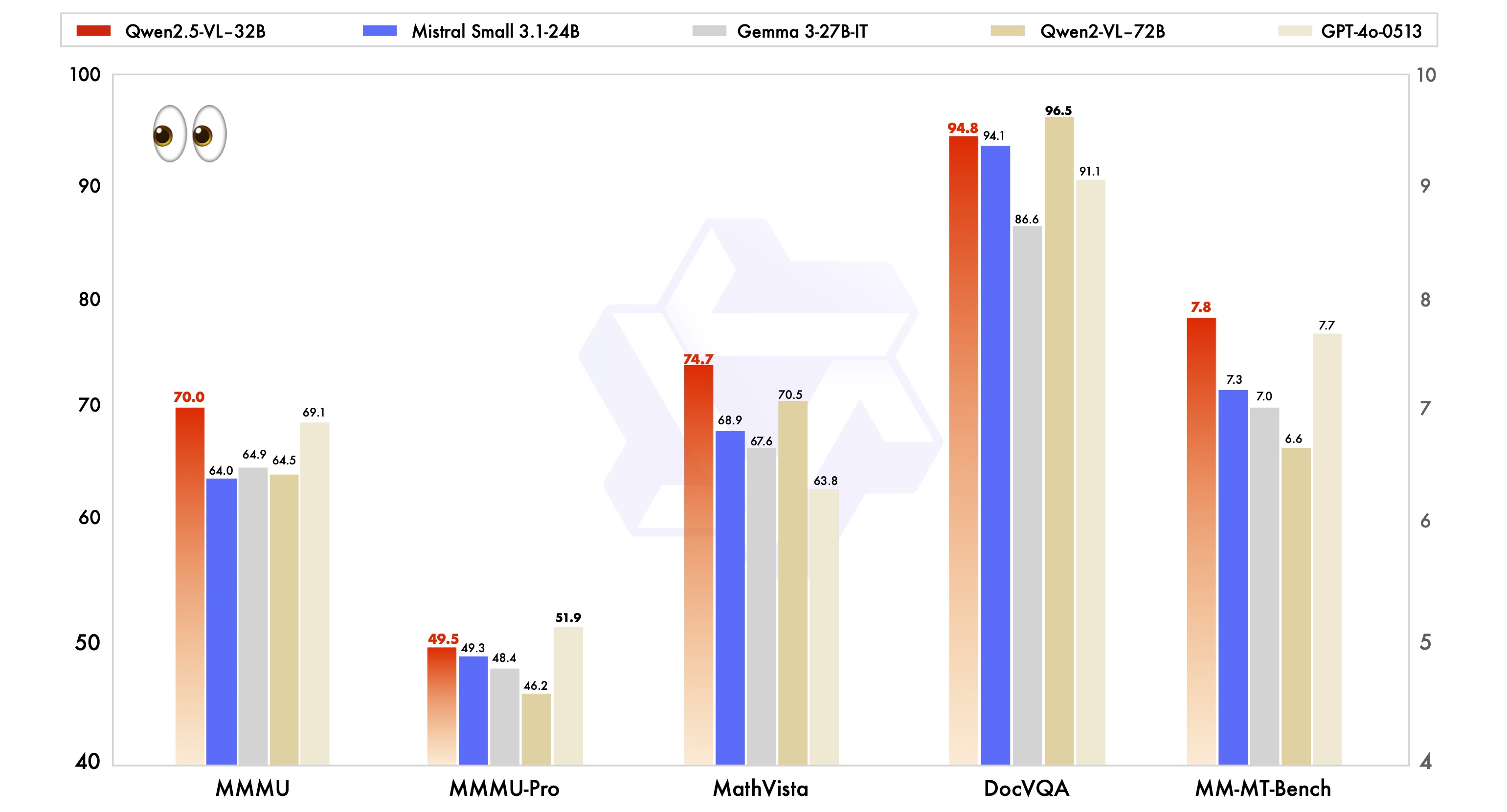
性能面でも注目されており、Qwen2.5-VL-32BはMistral-Small-3.1(24B)、Gemma-3-27Bといった同規模の他社オープンソースモデルと比較しても、マルチモーダル領域だけでなく純粋なテキスト生成能力においても同等以上のベンチマーク結果を記録している。さらに、72Bの上位モデルと比較しても一部タスクでは凌駕しており、効率と精度のバランスを求める現場にとって現実的な選択肢となっている。
公開形態も柔軟で、Hugging Face ではモデルのコード・パラメータ・トークナイザーが一式提供されており、容易にローカル実装・ファインチューニングが可能。中国国内ユーザー向けには ModelScope でも同様にモデルファイルが配布されている。また、対話型の実演として Qwen Chat 上でもQwen2.5-VL-32B-Instructを体験可能であり、実用シーンを想定したブラウザベースでの検証が手軽に行える。
さらに、開発元が公開している公式技術ブログでは、本モデルのアーキテクチャ概要、訓練データの構成、ベンチマークスコアやユースケースなどが豊富に掲載されており、研究者や開発者が技術的背景を深く理解するうえでの貴重な情報源となっている。
Qwenシリーズは、近年の中国におけるオープンソースAI開発の象徴とも言える存在であり、DeepSeekやBaichuan AIなどの動向と並び注目を集めている。今回のリリースもまた、単なるモデル公開にとどまらず、世界的なAIエコシステムとの接続性を意識した戦略的な一手として捉えられる。