中国のAIスタートアップDeepSeek AIは、自社の大規模言語モデル「DeepSeek-V3」を小規模アップデートし、「DeepSeek-V3-0324」として新たに公開した。今回の更新では、APIや使用方法は従来のまま維持されつつ、ユーザーが対話画面で「深度思考」モードをオフにすることで、即座に新モデルの使用が可能となっている。
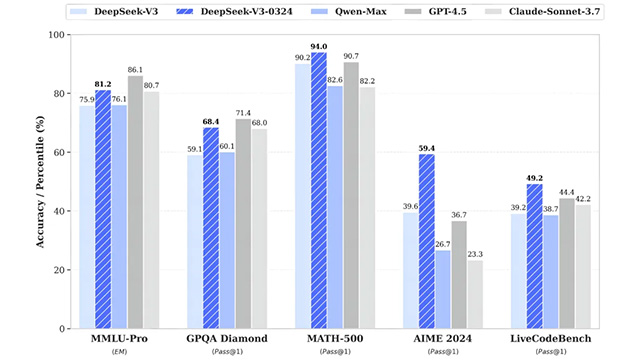
最大の特徴は、DeepSeek-R1の訓練プロセスで使用された強化学習技術を導入した点であり、これにより推理関連タスクの精度が大幅に向上。具体的には、数学(MATH-500, AIME 2024)やコード生成(LiveCodeBench)、百科知識系のベンチマーク(MMLU-Pro, GPQA)でGPT-4.5を上回るスコアを記録した。
さらに、HTMLなどのフロントエンド開発においてもコードの可読性や視覚的美しさが向上し、例えばp5.jsによるインタラクティブなビジュアル生成やサイバーパンク調のデザインなど、デモンストレーションでも洗練された表現力を見せている。
また、中国語の生成能力にも重点が置かれ、中長文の創作において内容の一貫性や表現の豊かさが向上。ネットワーク検索を活用するレポート出力では、情報の網羅性やレイアウトの整備にも改善が見られた。
加えて、ツール呼び出し、ロールプレイ、カジュアルな対話といった多様な用途でも性能が底上げされている。
「DeepSeek-V3-0324」は前バージョンと同じbaseモデルを利用しており、主に後訓練方法が改良された。モデルパラメータは約660B、文脈長は最大128K(Web・App・APIでは64Kまで)。オープンソースバージョンはMITライセンスの下で提供され、商用利用や蒸留モデル開発も許可されている。