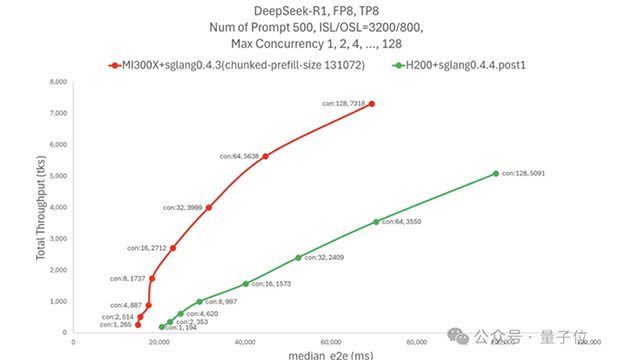
AMDのMI300Xが、生成AIモデルDeepSeek-R1の推論処理においてNVIDIAの最新GPU H200を圧倒する性能を示し、注目を集めている。AMDによると、同じ遅延条件でのスループットは最大でH200の5倍に達し、並列数を揃えた場合でもH200を75%上回る。特に、トークン間遅延を50ミリ秒以下に抑える条件下で、H200が16並列に対応するのに対し、MI300Xは128並列まで対応可能となっている。
この飛躍的な性能向上の背景には、SGLangと呼ばれるオープンソースの大規模モデル推論フレームワークの存在がある。SGLangはLMSYSが主導するプロジェクトで、AMDも主要な貢献者の一つ。DeepSeek-R1と高い親和性を持ち、MI300XだけでなくNVIDIA製GPUでも性能向上に寄与している。テストでは、SGLang導入によりMI300X上のスループットが初期比4倍に成長した。
さらに、AMD独自のAIカーネルライブラリ「AITER」も重要な役割を果たしている。AITERは、ROCmエコシステム内で構築された高性能AI演算子の統合プラットフォームで、GEMM演算、MoE、MLA、MHAといった処理の性能を最大17倍まで向上させる。DeepSeek-V3では、AITER有効化によりスループットが2倍以上となった。
加えて、AMDはハードウェアに合わせた超パラメータ調整も実施。128以上のスレッド処理時に発生するプリフィル遅延を解消するため、chunked_prefill_sizeパラメータを拡大。MI300Xの大容量メモリを活用する形で処理速度を引き上げた。
これらソフトウェア最適化、AIエンジン強化、ハードウェア調整の三位一体の戦略により、MI300XはNVIDIAを凌駕する実行性能を実現。今後の大規模AI推論環境におけるAMDの存在感が一層強まりそうだ。