2025年3月18日、Kunlun Tech(昆崙万維)は、中国初となるマルチモーダル思考推論モデル「Skywork R1V」をオープンソースで公開した。視覚情報に対して段階的な思考プロセス(Chain-of-Thought)を適用し、単なる画像認識を超えて論理的な推論を実行できる点が最大の特徴となっている。視覚とテキストを統合した推論能力を備え、学術・教育・医療・産業応用など多様な領域での活用が期待されている。
Skywork R1Vは、芸術作品に関する文脈理解、視覚ベースの数学・物理問題の解答、医学画像の診断補助といった複雑で知的な処理タスクを高精度にこなすことが可能。実際に、画像に含まれる数学の選択問題を視認し、ステップ・バイ・ステップで解答へと導くデモンストレーションが紹介されており、従来のマルチモーダルモデルとは一線を画す「思考するAI」としての片鱗を見せている。
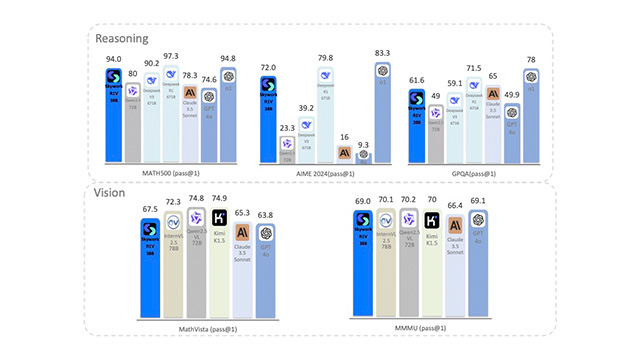
性能評価の面でも、Skywork R1Vは非常に高い指標を達成している。論理推論力を測るMATH500ベンチマークでは94.0、AIMEでは72.0というスコアを記録。さらにマルチモーダル推論に特化したMMMU(69点)やMathVista(67.5点)といった国際的ベンチマークでも、同規模の他のオープンモデルを大きく上回る成績を収めており、Skywork R1Vが単なる研究モデルではなく、実践的な推論能力を持つプロダクショングレードのAIであることが証明された。
この高性能の裏には、Kunlun Techによる3つの技術的革新がある。 第一に、テキスト推論能力のマルチモーダル転移。視覚入力とテキストモデルを結びつけるSkywork-VLという仕組みにより、もともと強力な言語モデルの論理力を画像タスクにも効率的に適用できる。特筆すべきは、視覚エンコーダや言語モデルを再学習せず、適応層(MLP)だけを訓練する方式を採用している点で、計算資源を抑えながら高い転移性能を実現している。
第二に、マルチモーダル混合学習(Iterative SFT + GRPO)を導入。視覚と言語のモダリティ間の表現を段階的に調整し、視覚認識においても言語的文脈に即した自然な推論を可能にしている。強化学習と教師あり学習を交互に活用し、学習の精度と安定性を両立させる構造となっている。
第三に、自適応長の思考チェーン蒸留(Adaptive Chain-of-Thought Distillation)を実装。タスクの複雑さに応じて推論ステップの長さを動的に調整することで、「考えすぎ」による非効率や過学習を防ぎ、推論過程を最適化している。これにより、パフォーマンスだけでなく処理効率にも優れたモデルが完成した。
加えて、Skywork R1Vは今後の全モーダル対応AIモデルへの拡張構想も明らかにしている。現在は画像とテキストの統合だが、今後は音声認識や動画理解などを統合し、単一のモデルで画像・映像・音声を一体的に処理できる「全モーダル思考モデル」への発展を目指す。すでにプロトタイプでは複数のSOTA(最先端)スコアを記録しており、音声-視覚統合AIの分野でも新たな基準となる可能性が高い。
Kunlun Tech(昆崙万維)は、これまでにも「Skywork 13B」や「SkyReels」など複数の大規模モデルを公開し、中国におけるオープンソースAIエコシステムの推進企業として存在感を示してきた。今回のSkywork R1Vの公開は、マルチモーダル思考推論という新たな技術領域における中国初の試みであり、国際的なAI開発競争において中国が果たす役割の拡大を象徴する出来事と言える。