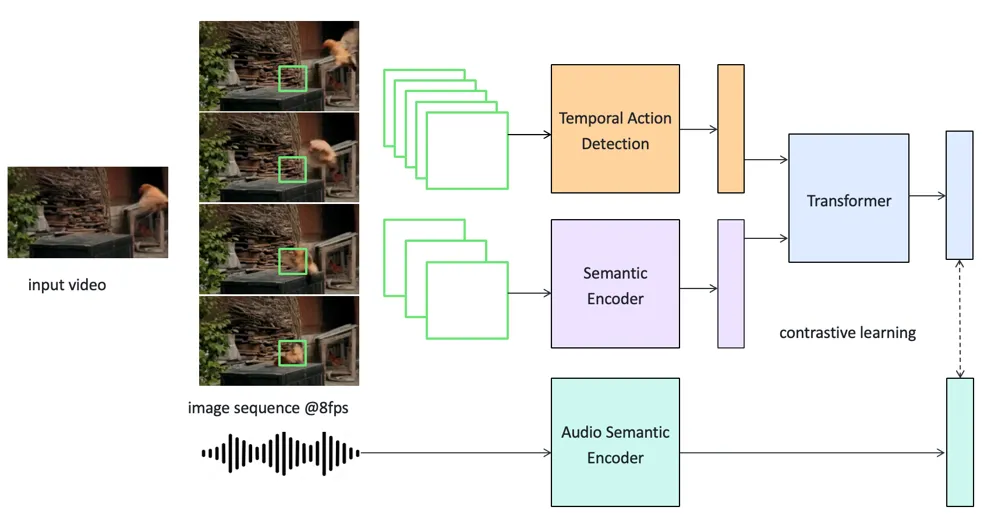
AI生成コンテンツ(AIGC)が動画生成の限界を次々と突破する中、音声制作は依然として業界発展のボトルネックとなっている。バイトダンスの豆包(Doubao)大規模モデル音声チームは、動画内の音声を自動生成するエンドツーエンドの「SeedFoley」モデルを開発し、AI動画制作を「有声時代」へと導いた。この技術により、動画の時空間特徴と拡散生成モデルを融合し、高度な音声同期を実現している。
具体的には、固定されたフレームレートで動画シーケンスからフレームを抽出し、動画エンコーダーで特徴情報を取得。その後、複数の線形変換を通じて特徴を条件空間に投影し、改良された拡散モデルフレームワーク内で音声生成プロセスを構築する。このモデルは、可変長の動画入力をサポートし、音声の正確性、同期性、適合性などの指標で優れた成果を上げている。
「即夢AI(Jimeng AI)」の「AIサウンド」機能を使用すると、ユーザーは動画生成後にこの機能を選択することで、3つのプロフェッショナルな音声プランを自動生成できる。これにより、AI動画、生活Vlog、短編制作、ゲーム制作などの高頻度シーンで、AI動画の「無音の気まずさ」を解消し、プロフェッショナルな音声付きの高品質な動画を手軽に制作できる。
「SeedFoley」は、動画内容と音声生成の深い融合を実現し、フレームレベルの視覚情報を正確に抽出。複数フレームの画面情報を分析し、動画内の音声主体や動作シーンを正確に識別する。リズム感の強い音楽の瞬間や映画の緊張感あふれる場面でも、正確にタイミングを合わせ、臨場感あふれるリアルな体験を提供する。さらに、動作音声と環境音声をスマートに区別し、動画の叙述力と感情伝達効率を大幅に向上させる。
【関連リンク】
即夢AI(Jimeng AI)公式サイト:https://jimeng.jianying.com/ai-tool/home