アリババグループのTongyi Lab(通義実験室)に所属する薄列峰チームが、視覚と音声を含む全モーダル大規模言語モデル「R1-Omni」を開発・公開した。最大の特徴は、DeepSeek-R1で注目されたRLVR(可検証報酬による強化学習)を、初めて音声と画像の統合処理を行う全モーダルLLMに適用した点にある。
RLVRは、人間のフィードバックに基づく強化学習(RLHF)とは異なり、明示的な検証関数によりモデル出力を直接評価・最適化する仕組み。さらに、比較ベースの強化学習手法GRPOを組み合わせ、外部の「評価者」モデルを使わずに出力の質を効率的に学習する。
モデルの推論結果はHTML形式で構造化され、<think>タグ内に推論過程、<answer>タグ内に予測された感情が表示される。これによりモデルが視覚・音声のどの情報からどのように結論を導いたかを可視化し、説明性を大きく高めている。
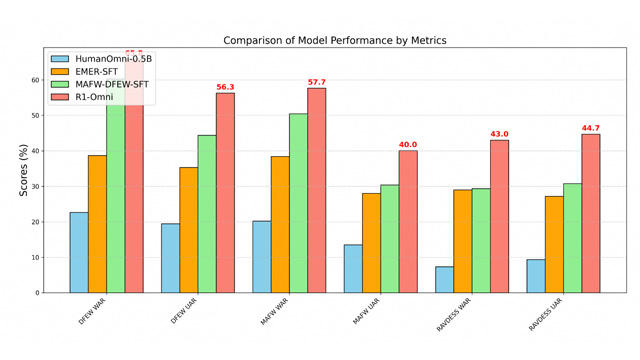
性能評価では、既存の3モデル(HumanOmni-0.5B、EMER-SFT、MAFW-DFEW-SFT)と比較して、R1-Omniは推論力、理解力、そして未知データに対する汎化性能の全てで上回る結果を示した。特にRAVDESSのような映画以外の音声データにも強く、実用性の高さが裏付けられている。
GitHub上では、ベースとなるHumanOmni-0.5Bを含め、訓練コード、評価スクリプト、事前学習済みモデル(SFTモデル・RLモデル・最終モデル)などが一式公開されており、研究者が実験を完全に再現できる構成となっている。また、インストールガイドやデータ準備手順、トレーニングスクリプトなども詳細に整備されている。
この取り組みは、単なる研究成果の発表にとどまらず、次世代マルチモーダルAIの開発と応用の加速につながる重要なステップとして注目されている。
【関連リンク】
GitHubプロジェクトページ:https://github.com/HumanMLLM/R1-Omni
arxiv論文:https://arxiv.org/abs/2503.05379