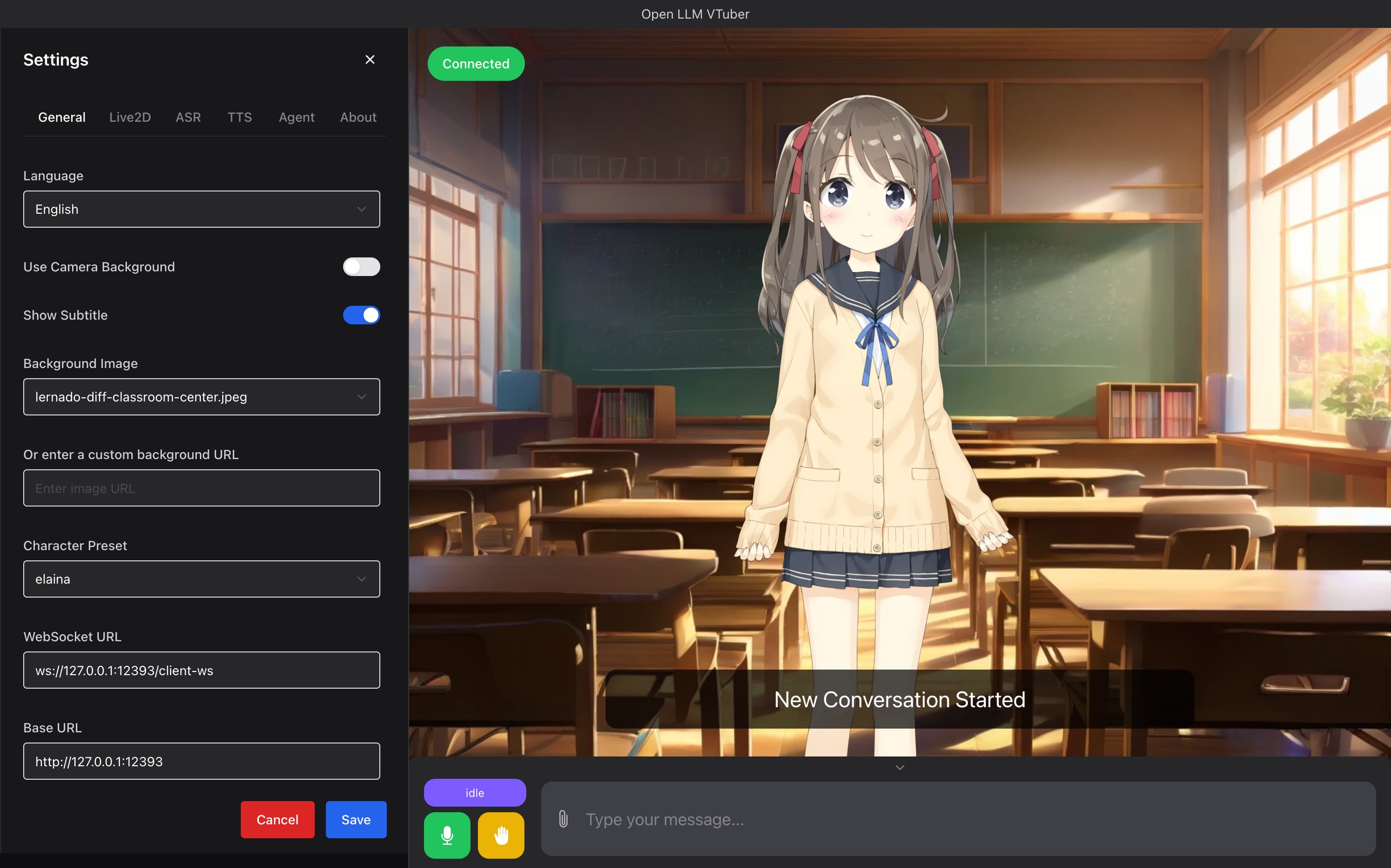
「Open-LLM-VTuber」は、音声認識・表情認識機能・Live2Dアニメーションを統合した、オープンソースのリアルタイムAI VTuber開発プラットフォームである。2024年2月18日にバージョン1.1.0が公開され、ローカル環境での実行を前提とした高機能かつ拡張性の高いアーキテクチャが特徴となっている。中国語圏の開発者コミュニティによって構築されており、GitHub上ではコード・ドキュメント・Webデモ環境などが整備されている。
音声入力にはWhisperやVoskといったオープンソースのASR(自動音声認識)エンジンを使用し、ユーザーの発話をリアルタイムでテキストに変換。その後、ChatGPT、Claude、LangChainなどから選択可能な大規模言語モデル(LLM)がテキストを処理し、自然な応答を生成する。生成された返答は、ElevenLabs、Coqui TTS、中国語TTSなどにより音声出力され、必要に応じてAIボイスチェンジ機能も追加可能である。
視覚的なインタラクションにおいては、Webカメラを用いた表情認識機能によりユーザーの表情や視線を検知し、Live2D SDKによってリアルタイムにキャラクターの表情や動作に反映させる。これにより、AIキャラクターがまるで“感情を持っているかのように”自然に反応する演出が可能となる。また、GradioベースのWeb UIが同梱されており、ユーザーはブラウザ上で手軽に動作確認や操作が行える。
プロジェクト全体はPythonで記述されており、各機能がモジュール化されているため、利用者はTTSやASR、LLMのエンジンを自由に切り替えたり、キャラクターや音声を個別にカスタマイズしたりできる。Docker対応やGPU対応など、開発者向けの環境構築ガイドも充実している。
Open-LLM-VTuberは、配信者向けVTuberキャラクターや個人用AIパートナーだけでなく、バーチャル受付スタッフや業務向け案内システムといった実用的な用途にも応用可能な汎用性を持っている。リアルタイムで自然なAIインタラクションを目指す技術的な試みにおいて、注目すべきオープンソースプロジェクトの一つといえる。
【関連リンク】
GitHubリポジトリ:https://github.com/Open-LLM-VTuber/Open-LLM-VTuber