DeepSeekチームは、コードを思考プロセスとして活用する新たなデータセット「CODEI/O」を開発し、QwenやLlamaなどの大規模言語モデルを訓練した。従来、コードのトレーニングは主にプログラミング能力の向上を目的としていたが、今回の研究では、コードを通じて多様な推論パターンを抽出し、モデルの推論能力全般を向上させることが確認された。
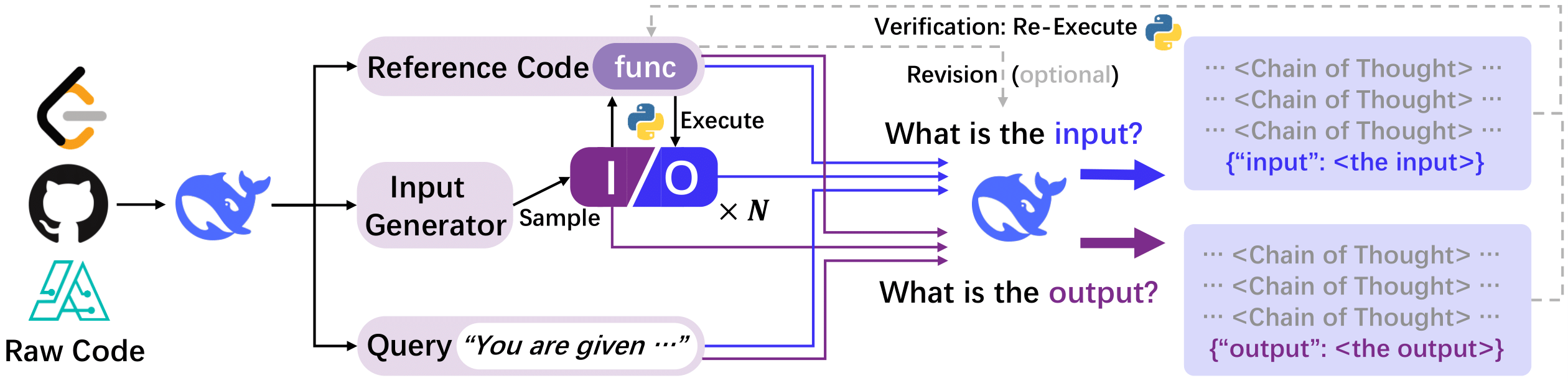
研究チームは、Pythonを中心とした多様なプログラミング言語の80万以上のコードファイルを収集し、DeepSeek-V2.5モデルを用いて統一フォーマットに変換。次に、入力-出力ペアと機能説明を組み合わせ、自然言語形式の思考プロセス(Chain-of-Thought, CoT)を生成した。この「CODEI/O」に加え、コードの実行フィードバックを活用してデータ品質をさらに高めた「CODEI/O++」を作成。誤った推論結果には実行エラー情報を追加し、再学習を行うことでデータの精度を向上させた。
評価では、Qwen 2.5-7B-Coder、DeepSeek v2-Lite-Coder、Llama 3.1-8B、Gemma 2-27Bの4つのモデルを用い、数学、物理、工学、一般常識など10以上のデータセットで性能を検証。その結果、LlamaはLeetCode-Oで約150%の性能向上を達成し、Gemmaは大規模モデルにおいてもCODEI/Oの有効性を示した。さらに、CODEI/OはWebInstruct(WI)よりも優れた効果を示し、特定分野に特化したOpenMathInstruct2(OMI2)やPyEduと比較しても高い汎用性を発揮した。
本研究の第一著者は上海交通大学の修士課程に在籍するJunlong Li氏で、香港科技大学の何俊賢助理教授の指導のもと研究を実施。DeepSeekの開発チームには中山大学出身の郭達雅氏も参加し、DeepSeek V2、V3、R1の開発にも関与している。
詳細は以下のリンクで公開されている。
論文: https://arxiv.org/abs/2502.07316
GitHub: https://github.com/hkust-nlp/CodeIO
データセット: https://huggingface.co/datasets/hkust-nlp/CodeIO-PyEdu-Reasoning
DeepSeekチーム、コードを思考プロセスに変換し大規模モデルの推論能力を向上
出典:https://mp.weixin.qq.com/s/2Xb8hdrZe0JcLjBdKfktkQ
概要ポイント
- DeepSeekチームが「CODEI/O」を開発し、コードを思考プロセスに変換。
- QwenやLlamaなどのモデルをトレーニングし、推論能力が向上。
- 実行フィードバックを活用した「CODEI/O++」でデータ品質を強化。
- LlamaはLeetCode-Oで約150%の性能向上を達成。
- 大規模モデルGemmaでも有効性が確認され、幅広い応用可能性を示唆。
本文