小紅書と上海交通大学は、多モーダル大規模モデル(MLLMs)の実世界における理解力を評価する新たなベンチマーク「WorldSense」を発表した。これは、AIが視覚・音声・テキスト情報をどの程度統合して認識できるかを測定するために開発された。従来のベンチマークが個別のモーダル情報に焦点を当てていたのに対し、WorldSenseはより現実的なシナリオを想定し、音声と映像の強い結びつきを持つタスクを設定している。
この基準は、8つの主要分野と67の細分化されたカテゴリに分類された1,662本の視聴覚同期動画と、3,172の多肢選択式質問を含み、AIの多様なシナリオでの認知能力を包括的に評価する。また、すべてのデータは80人の専門家によって手動で注釈付けされ、複数回の修正を経た高品質なデータセットとなっている。
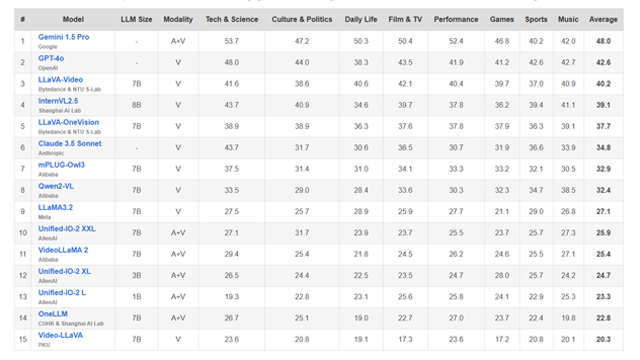
評価の結果、オープンソースの動画・音声統合モデルの正答率はわずか25%と、ランダムな推測とほぼ変わらないレベルだった。最も高性能なGemini 1.5 Proでも正答率は48%にとどまり、実世界での信頼性にはまだ遠いことが示された。また、いずれかのモーダル情報が欠けると正答率が約15%低下することも確認され、AIが情報を統合的に処理する能力の重要性が浮き彫りになった。
さらに、詳細な分析では、音声関連タスクでの成績が特に低く、音色や周波数情報の処理が難しいことが判明した。感情認識においても、音声トーンや表情を統合して理解する能力が不足していることが指摘されている。加えて、動画のフレーム密度を上げることで一部のモデルの精度が向上することが確認され、映像情報の活用が今後のAIの発展において重要な鍵となると考えられる。
この研究は、現行のMLLMsが多モーダル情報を完全に統合し、実世界の状況を理解するには、まだ多くの技術的課題があることを示している。今後の開発では、視覚・音声・テキストの統合理解能力を向上させるためのモデル設計や学習手法の改善が求められる。
プロジェクト公式サイト:https://jaaackhongggg.github.io/WorldSense
小紅書と上海交通大学、新たな多モーダルAI評価基準「WorldSense」を発表──Gemini 1.5 Proの正答率は48%に留まる
出典:https://mp.weixin.qq.com/s/9wOiVcTed7n19p2EUtnikg
概要ポイント
- 小紅書と上海交通大学が多モーダルAI評価基準「WorldSense」を発表。
- WorldSenseは視覚・音声・テキストを統合するAIの理解力を評価。
- 1,662本の視聴覚同期動画と3,172の多肢選択式質問を用意。
- 最新MLLMsの正答率は最高でも48%にとどまり、実世界応用には不十分。
- AIの多モーダル統合能力向上が今後の重要課題。
本文