2月2日、清華大学や上海交通大学、復旦大学の教授陣が、DeepSeekの技術的進展についてオンラインで議論を交わした。主なテーマは、DeepSeekがCUDAの制約を回避し、ハードウェア性能を最大化できたのかという点だった。議論では、DeepSeekが採用したPTX(Parallel Thread Execution)の最適化が詳細に解説された。
PTXはCUDAのドライバ層の下に位置する低レベルのプログラミング言語で、通常のAIエンジニアには直接扱われることが少ない。しかし、DeepSeekはPTXを活用し、通信チャンクサイズの自動調整を行うことで、L2キャッシュの使用を最適化し、GPU内の干渉を抑えた。このアプローチにより、計算効率の向上が図られたが、一部の報道で言われるような「CUDAの完全な回避」については、教授陣から異論が出た。CUDAはハードウェアとソフトウェアの橋渡しとして不可欠な要素であり、PTX最適化はCUDAを完全に排除するものではなく、あくまでその内部を高度に活用する手法であるとの見解が示された。
また、DeepSeekの低コストでの大規模モデル再現も注目された。GPT-4oのようなモデルを従来の1/10のコストで再現できた点は、AI業界にとって大きな転換点となる可能性がある。特に、中国のAI技術が「算力封鎖」に直面する中で、限られたリソースを最大限に活用することの重要性が強調された。
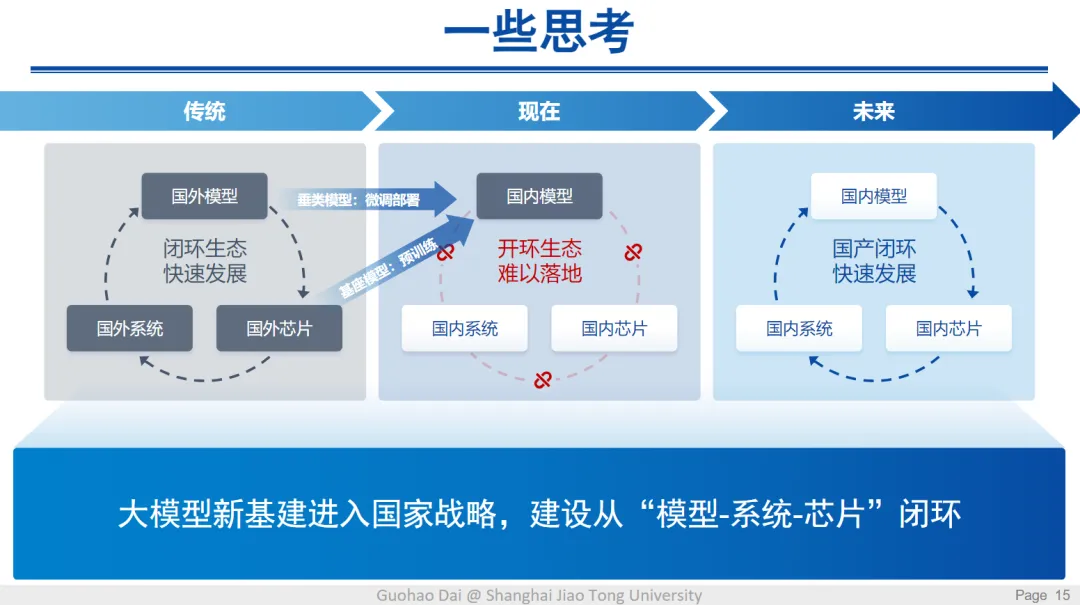
さらに、AI技術の発展においてソフトウェアとハードウェアの協調最適化が不可欠であることが指摘された。国内では、DeepSeekのような大規模モデルと国産チップを組み合わせることで、独自のAIエコシステムを構築する動きが加速している。既にHuaweiの昇騰プラットフォームへの移植が進んでおり、今後も国内チップとの連携が活発化する見通しだ。
今回の議論を通じ、DeepSeekの技術革新が中国AI産業の未来に大きな影響を与えることが示唆された。CUDAの制約を乗り越えるための新たなアプローチ、低コストでの大規模モデル構築、そしてソフト・ハードの最適化による効率向上は、今後のAI技術開発の重要な方向性となるだろう。
解説:CUDAとは?
CUDA(Compute Unified Device Architecture)は、NVIDIAが提供する並列コンピューティングプラットフォームおよびAPIのセットで、GPUを活用して大規模な計算処理を行うための技術です。通常、ディープラーニングや科学技術計算などの分野で使用され、PythonのPyTorchやTensorFlowといったフレームワークを通じて利用されることが多い。CUDAはNVIDIA製のGPUに最適化されているため、現在のAI技術の発展において重要な役割を果たしているが、その独占性が課題とされることもある。
DeepSeekの技術革新とCUDAの壁:PTX最適化がもたらす影響
出典:https://mp.weixin.qq.com/s/V9BjKDvjEAzvYxJF-A9NDA
概要ポイント
- DeepSeekの最適化技術:PTXの活用により、ハードウェア性能を最大限に引き出す試み。
- CUDA回避の真相:「CUDAの壁を超えた」とする報道に対し、異なる見解も存在。
- ソフトウェアとハードウェアの協調最適化:PTXによる最適化が国内AI技術発展の鍵。
- 低コストでの大規模モデル再現:DeepSeekは限られたリソースで最適化を実現。
- 中国AI産業の展望:国内チップとの連携で独自のAIエコシステム構築を目指す。
本文