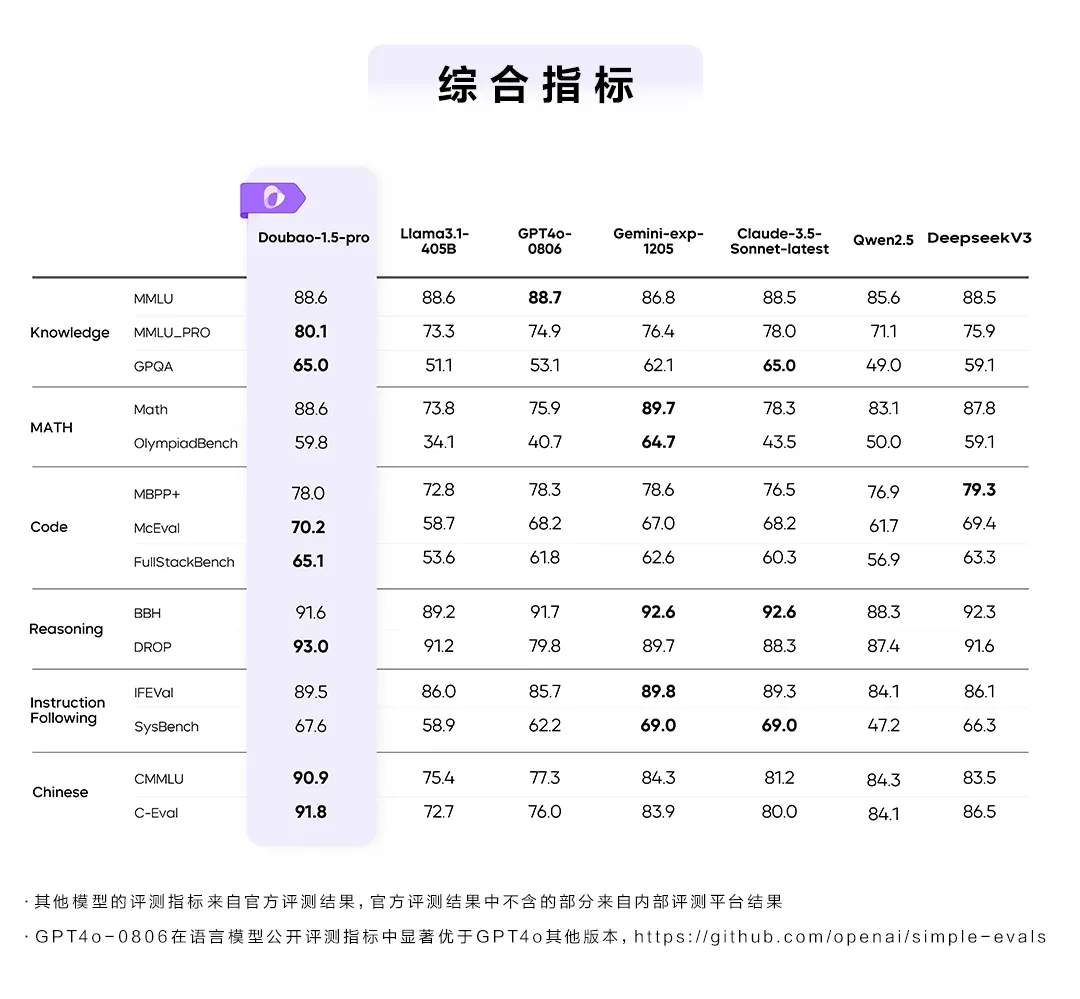
ByteDance傘下の豆包(Doubao)チームは、新世代の大規模言語モデル「豆包1.5Pro」を正式に発表した。本モデルは、知識(MMLU_PRO、GPQA)、コード(McEval、FullStackBench)、推論(DROP)、中国語(CMMLU、C-Eval)などの公開ベンチマークで高評価を獲得し、従来モデルを大幅に上回る性能を示した。
豆包1.5Proは、大規模なMoE(Mixture of Experts)アーキテクチャを採用することで、少ないアクティブパラメータで高効率な推論を実現し、計算コストの最適化を図った。従来のMoEモデルと比較して、計算効率は約3倍向上しており、計算リソースの活用効率も大幅に改善された。また、独自開発のネットワークプロトコルを最適化し、通信の安定性を確保しつつ、分散推論の性能を向上させた。
さらに、本モデルでは多モーダル処理の強化が図られ、視覚理解と音声処理の精度が向上した。新たに導入された「Doubao-1.5-vision-pro」は、視覚認識分野において最先端の性能を発揮し、「Doubao-1.5-realtime-voice-pro」はSpeech2Speechのエンドツーエンドフレームワークを採用することで、方言や歌唱を含む自然な発話生成が可能となった。これにより、従来の音声AIモデルと比較して、表現力とリアルタイム性の両面で優位性を確立した。
豆包チームは、モデルの訓練データについても独自のアプローチを採用し、他のAIモデルが生成したデータを一切使用しない体制を構築している。ラベリングチームと自己学習技術(self-play)を組み合わせることで、データの品質と多様性を確保し、高い信頼性を持つトレーニングデータの生成を実現した。これにより、モデルの独立性と信頼性が強化され、より安定した学習環境が整備された。
また、豆包1.5Proは、豆包アプリを通じて提供されるほか、開発者向けにAPIも公開されている。火山引擎(VolcEngine)を通じて外部サービスとの統合が可能となり、より多くの企業や開発者が豆包1.5Proの高性能なAI機能を活用できる環境が整った。
豆包チームは、今後も長期的な研究開発を継続し、さらなる多モーダル対応の進化や計算効率の向上に取り組む方針を示している。AGI(汎用人工知能)に向けた基礎研究を推進し、AI技術の新たな展開を目指す中で、豆包1.5Proの進化がどのような影響をもたらすのか、業界の注目が集まっている。
「豆包1.5Pro」正式発表:多モーダル・推論能力を大幅強化
出典:https://mp.weixin.qq.com/s/C6vm5zERKm9_3OCIQrbLJA
概要ポイント
- 豆包1.5Pro発表:知識・コード・推論・中国語などの分野で高性能を発揮。
- 高効率なMoEアーキテクチャ:従来比3倍の計算効率向上と低コスト化を実現。
- 多モーダル対応強化:視覚認識・音声生成の精度向上により表現力を拡大。
- 独自データ運用:外部AIモデルのデータを使用せず、独自の高品質データを活用。
- API提供:豆包アプリと火山引擎経由で開発者向けにサービスを開放。
- 今後の展望:AGI研究を推進し、多モーダルAIの進化を目指す。
本文