中国のAI企業・智譜(Zhipu AI)は、強化学習を活用した新たな推論モデル「GLM-Zero-Preview」を発表した。GLMシリーズの最新モデルとして、特に数学、コード、論理推論といった高度な推論能力を要する分野に特化している。このモデルは、強化学習による拡張を行いながらも、既存のGLM基盤モデルの一般的なタスク処理能力を損なうことなく、推論力を向上させることに成功している。
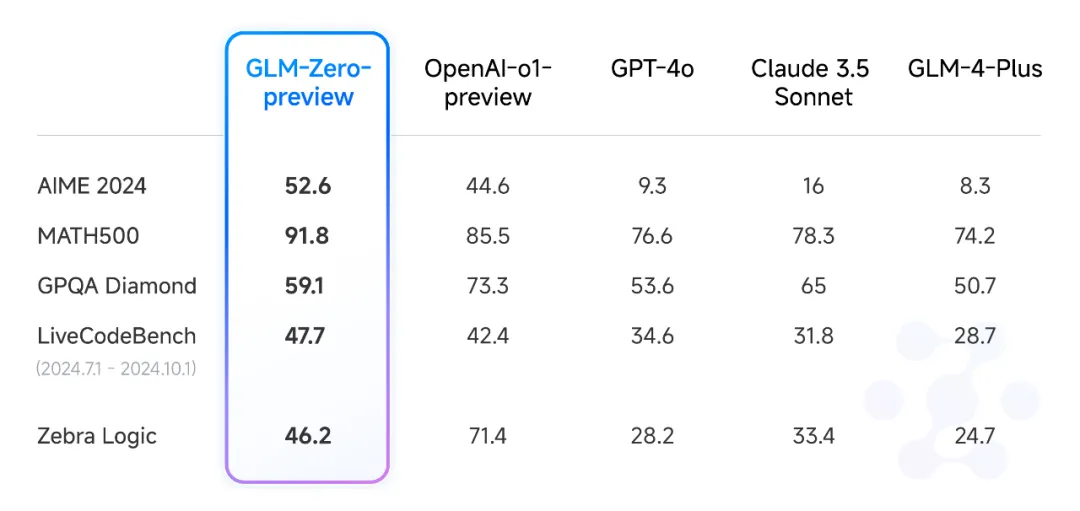
ベンチマークテストでは、AIME 2024、MATH500、LiveCodeBenchなどの評価において、OpenAIのo1-previewモデルと同等の性能を発揮した。この結果からも、GLM-Zero-Previewが数理的推論において高いパフォーマンスを発揮することが示された。
GLM-Zero-Previewは現在、「智譜清言」(chatglm.cn)において無料で提供されており、ユーザーはテキストや画像を入力することで、モデルの推論過程を確認できる。また、「智譜開放平台」(bigmodel.cn)では、APIを通じて開発者向けに提供されている。
実際の利用例として、GLM-Zero-Previewは論理推論に優れ、問題の構造を理解し、複数の仮説を検討した上で解を導き出す能力を持つ。あるテストケースでは、画像に含まれる数値を解析し、数字の回転による錯視を考慮して正しい解を導き出した。また、数学領域では、代数、微積分、確率統計など幅広い分野の問題に対応し、2025年の大学院入試レベルの数学試験では126点を記録。コード生成においても、多言語対応のプログラミング能力を持ち、指示に基づいたゲームの作成や、コードの自動デバッグが可能であることが確認されている。
現在のGLM-Zero-Previewは、OpenAIのo3モデルに比べてまだ課題が残るものの、智譜は今後さらなる強化学習の最適化を行い、より汎用的な推論モデルへと進化させる計画を発表している。次の正式版では、数理推論を超えた広範な分野への適用が予定されており、AIによる推論能力の向上が期待される。
公式サイト:https://chatglm.cn/
GLM-Zero Preview版リリース:強化学習による深層推理モデルの進化
出典:https://mp.weixin.qq.com/s/KHYMKASkHrj3Zn6nAb0jCw
概要ポイント
- GLM-Zero-Previewは、GLMシリーズの新しい推論特化型モデル。
- 強化学習を活用し、数学・コード・論理推論における性能を強化。
- AIME 2024やMATH500などのベンチマークで高評価を獲得。
- 無料で提供され、「智譜清言」や「智譜開放平台」経由で利用可能。
- 将来の正式版では、推論能力のさらなる拡張を予定。
本文