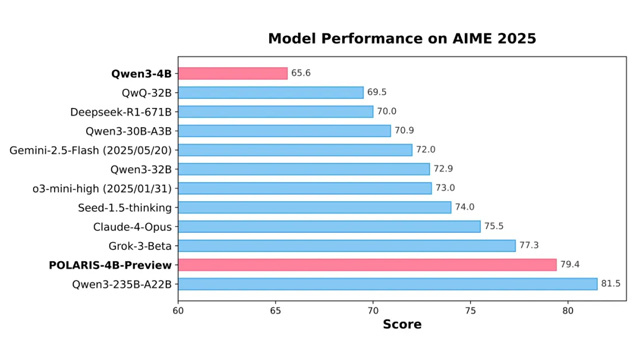
バイトダンスのSeedチームは、香港大学・復旦大学と共同で、小型LLM向けの強化学習手法「POLARIS(Policy Optimization for Lightweight And Robust Inference Systems)」を開発した。Qwen3-4Bを用いた実験では、AIME24/25において79.4〜81.2%の正答率を記録し、235Bクラスの大型モデルに迫る数学推論性能を実現している。
POLARISでは、訓練対象モデルに最適化した訓練データと超パラメータ設定を導入。サンプルの難易度を動的に調整することで、過学習や簡単すぎる課題を排除し、効率的な学習を実現する。加えて、生成の多様性を維持するため、訓練中のサンプリング温度を段階的に変更する「探索制御ゾーン」戦略を採用し、最適な温度範囲を動的に適用することで性能を安定化させた。
長文推論の性能を高めるため、事前学習済みの最大文脈長32Kを超える領域において、位置エンコーディングを外挿する「YaRN」方式を採用。これにより長文推論時の正答率が26%から50%以上へと向上した。初期段階から40Kトークンで訓練を行う戦略により、後の段階でも安定した性能向上が得られたことが報告されている。
最終的に、Qwen3-1.7B、DeepSeek-R1-Distill-Qwen-7B、Qwen3-4Bといった複数モデルでPOLARIS訓練を実施し、AIME24/25を含む5つのベンチマークにおいて平均10点以上の精度向上を達成。すべての訓練コードと設定はGitHub上で公開されており、再現・応用が可能となっている。