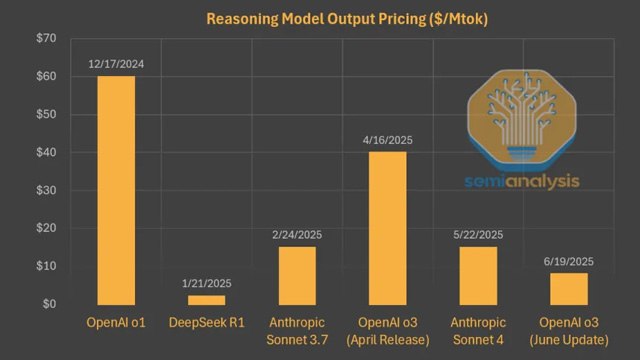
2024年末に登場した中国の大規模言語モデル「DeepSeek R1」は、当時の最先端モデルよりも90%以上安い価格設定で注目を集めた。R1はコード生成や長文推論に特化し、OpenAIと肩を並べる性能を示したが、DeepSeekが目指したのは商業的成功ではなく、演算資源を最大限に活かしたAGIへの前進だった。
この選択は数値的にも現れている。自社サービスでの使用量は低下傾向にある一方、OpenRouterなどの外部プラットフォームではDeepSeekモデルの使用量が20倍近くに増加した。この乖離の要因は、トークン経済(Tokenomics)と呼ばれるKPIバランスにある。DeepSeekは極限までコストを削減するため、トークン生成の初速を犠牲にし、コンテキストウィンドウも64Kと小規模に抑えている。これによりモデル応答は遅く、ユーザー体験は劣るものの、1トークンあたりの計算効率は群を抜く。
同様の戦略はAnthropicも採用しており、Claudeシリーズもコード生成特化によってトークン消費型のサービスで存在感を強めている。ただし、Anthropicはユーザー体験とのバランスを意識しており、DeepSeekのように徹底的に体験を犠牲にする姿勢は取っていない。Claude CodeやGemini CLIなどの台頭が示すように、今後はAPIベースでのトークンサービスが主流となる可能性が高い。
一方で、DeepSeekは独自の思想に基づき、算力制約を研究に集中させるため、トークン生成の高速化やUX改善を敢えて放棄している。推論は外部に委託し、自社の計算資源はすべてAGIに向けた訓練に投入するというスタンスだ。R1はすでに最新バージョンでコード性能を大きく向上させており、価格性能比では依然として業界屈指の競争力を持つ。R2のリリースが遅れているとの報道もあるが、推論能力よりも訓練能力に重点を置く姿勢は変わっていない。
DeepSeekは、トークンあたりの“賢さ”を追求することがモデル最適化の鍵であるとし、既存の商業モデルとは異なる道を進む。AI開発がトークン経済と共に再構築される中、DeepSeekのような“実験室型AI企業”が次世代の枠組みを先取りしている可能性がある。