アリババグループ傘下のTongyi Lab(通義実験室)は、画面の構造的理解を通じて論理的に音を生成する新しい音声AI「ThinkSound」を公開し、GitHub等でオープンソースとして配布を開始した。
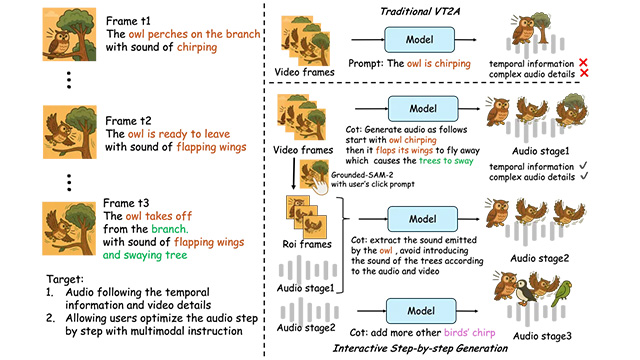
従来の映像-to-音声(V2A)生成技術では、映像内の物体や動作に対する音声の同期性が不十分で、音と画のズレが専門的な制作現場での活用を難しくしていた。ThinkSoundはこの課題に対し、Chain-of-Thought(思考の連鎖)推論を応用することで、AIが映像内のイベントを人間の音響技師のように段階的に理解し、画面に“耳を傾ける”ようにして音を生成する構造を持つ。
同モデルは、「AudioCoT」と名付けられた2,500時間超の多モーダル音響データセットを活用。VGGSoundやAudioSetなど複数の既存データに加え、細粒度な手動校正と自動フィルタリングにより構築された。さらに、物体単位の描写とユーザー指示による音声編集の双方に対応する構造を備え、インタラクティブな音響体験も可能にしている。
ThinkSoundは三段階の推論プロセスで音声を生成する。まず映像全体から動作や場面を把握し、次に猫や車といった対象物ごとの音響推論を実行、最後に「○○の後に××の音を加えてほしい」といった自然言語のユーザー指示にも対応し、リアルタイム編集可能な音声を合成する。
技術面では、マルチモーダル大規模言語モデル(MLLM)と、音声出力に特化した音響生成モジュールが連携。VGGSoundベンチマークでは、従来のMMAudioやV2A-Mappeを大きく上回るスコアを記録し、Meta製のMovieGenAudioを凌駕する性能を示した。
同モデルは既にGitHub、HuggingFace、ModelScopeにて公開済みで、誰でもダウンロードして利用できる。今後は、より複雑な音響環境への対応や、VR/ARを含む没入型応用分野への展開が予定されている。